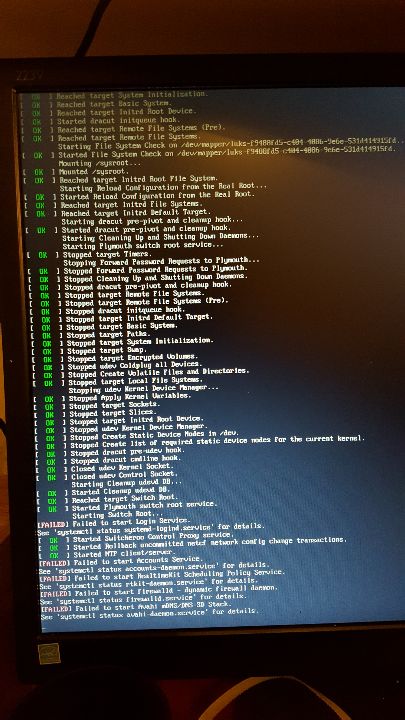
Es fing wie immer harmlos an, obwohl, tut es das nicht immer ? Hmm.. also.. es fing harmlos an :
Berlin: „0:10 Ping…Bist Du da ?“
Ich: „0:12 Ja, klar. Was gibt es denn?“
Berlin: „0:12 Mein Rechner bootet nicht mehr..Ich schick Dir mal ein Foto“
Womit das Unheil seinen Lauf nahm …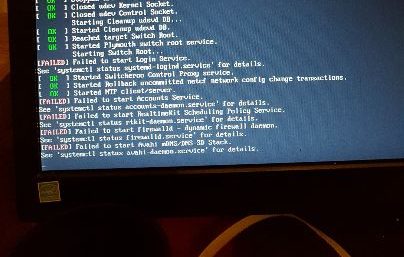 Ich: „Also logind geht nicht ? Starten wir doch mal mit einem anderen Kernel… “
Ich: „Also logind geht nicht ? Starten wir doch mal mit einem anderen Kernel… “
Berlin: „Mist, gleiches Ergebnis.“
Das ist natürlich eine Kaskade, wenn ein wichtiger Dienst nicht startet und andere auf den angewiesen sind, dann starten die auch nicht. Es wird daher nur eine Sache nicht gehen, das stand zu dem Zeitpunkt eigentlich schon fest.
Nun startet man den Rechner im Debugmodus…
Dazu im Kernelauswahlmenü auf die Taste „e“ drücken und in der Zeile mit „linux /vmlinuz….“ am ENDE “ 1″ anfügen. Dann mit STRG+X booten.
Was nun passiert ist, daß sobald ein Minimalsystem von der Platte startet, der Admin sein Passwort eingeben kann und in der Shell den Fehler beheben kann, wenn man ihn denn findet.
Ich: „schauen wir mal in die Logs vom letzten Boot.. journalctl –boot=-1“
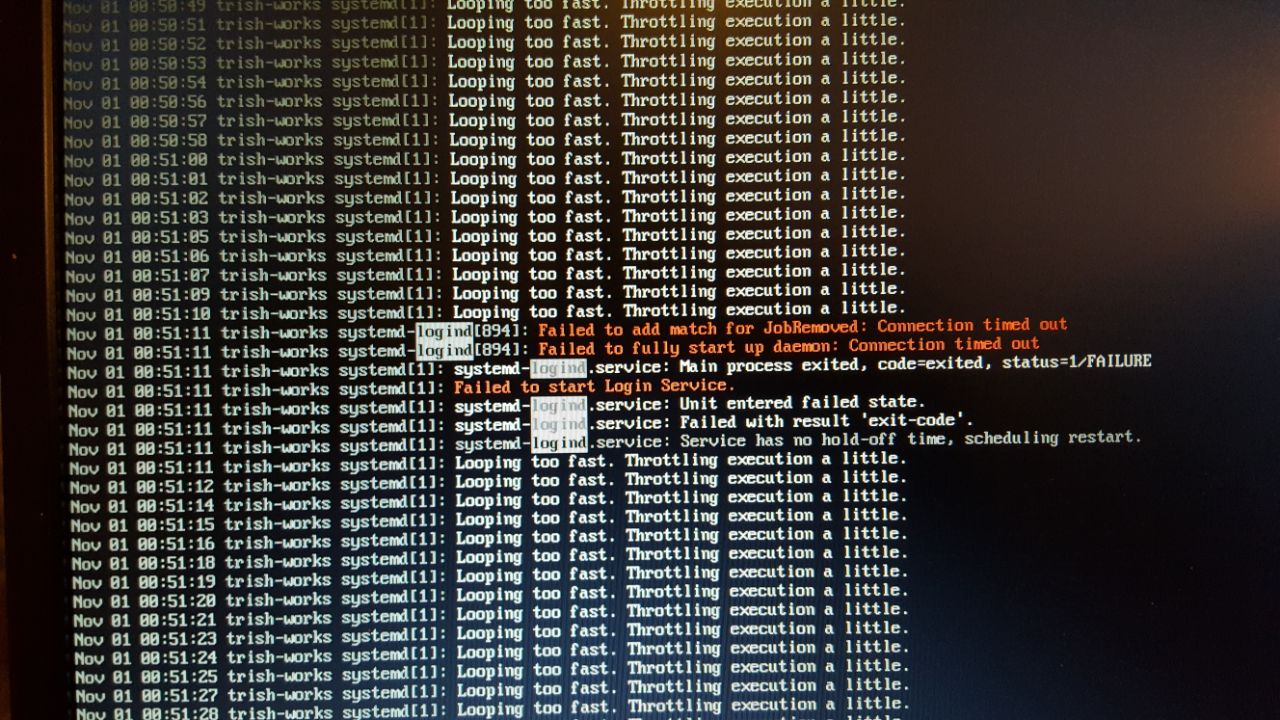 Ich: „Connection timed out… also hat er versucht einen Systemdienst zu kontaktieren, der nicht geantwortet hat. Wir starten den mal so, vielleicht gibt es noch mehr Ausgabe“
Ich: „Connection timed out… also hat er versucht einen Systemdienst zu kontaktieren, der nicht geantwortet hat. Wir starten den mal so, vielleicht gibt es noch mehr Ausgabe“
Ich: „systemctl start systemd-logind“
Berlin: „Nichts..“
Ich: „Also der logind will nicht… suchen wir mal die Service Datei“
[root /]# locate logind.service
/usr/lib/systemd/system/systemd-logind.service
/usr/lib/systemd/system/multi-user.target.wants/systemd-logind.service
/usr/share/man/man8/systemd-logind.service.8.gz
[root /]# cat /usr/lib/systemd/system/systemd-logind.service | grep Exec
ExecStart=/usr/lib/systemd/systemd-logind
MemoryDenyWriteExecute=yes
Ich: „Na dann starten wir mal systemd-logind von Hand. Gib ein was in der ExecStart hinter dem = steht“
Berlin: „Passiert nichts“
Ich: „Also jetzt müßte man strace benutzen, das traue ich Dir zu, aber die Ausgabe zu interpretieren ist eine Sache für sich. Ich muß auf Deinen Rechner.“
Zu dem Zeitpunkt liefen außer dem PID=1 Prozess noch genau 3 andere auf dem Rechner 😀
Ich: „start mal das Netzwerk … systemctl start network“
Berlin: „Geht nicht. Hängt.“
Ich: „Mist.. aber kein Beinbruch.. STRG+C und dann brauche ich mal die IP der Portfreigabe für SSH aus Deinem Fritz-Router.“
Jetzt muß man dazu wissen, daß man in der Fritzbox eine Portfreigabe für den SSHD machen kann und die leitet man auf die feste LAN IP des Pcs, den man von außen kontaktieren will. Das hat den Vorteil, daß der befreundete Admin, jederzeit helfen kann. Es setzt aber auch voraus, daß das Netzwerk da ist, was es nicht war…
Nachhilfe – Wie konfiguriert man eine Netzwerkkarte von Hand
Nachdem die IP kennt, gibt man ein:
ifconfig enp1s5 192.168.178.22 network 255.255.255.0 up
route add default gw 192.168.178.1
/usr/sbin/sshd
Wobei man hier natürlich die ermittelte IP einträgt und das richtige Netzwerkkarteninterface wählen muß. Wer seins nicht kennt, kann das mit „ip l“ auflisten:
# ip l
1: lo: <loopback,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000</loopback,
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: enp2s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000 link/ether 50:13:3e:47:35:31 brd ff:ff:ff:ff:ff:ff
Ab der Stelle kann man dann per SSH auf dem Rechner einloggen, was sehr praktisch ist. Es stellte sich jetzt recht schnell raus, daß die ganzen Programm dem Init Prozess eine Message schicken wollen, aber keine Antwort mehr bekommen. Was daran lag, daß der DBUS-Daemon nicht lief. Jetzt konnte man endlich suchen, was dafür die Ursache war und das geht z.b. so :
[root /]# locate dbus.service
/usr/lib/systemd/system/dbus.service
/usr/lib/systemd/system/multi-user.target.wants/dbus.service
/usr/lib/systemd/user/dbus.service
/usr/lib/systemd/user/dbus.service.d
/usr/lib/systemd/user/dbus.service.d/flatpak.conf
[root /]# cat /usr/lib/systemd/system/dbus.service | grep Exec
ExecStart=/usr/bin/dbus-daemon –system –address=systemd: –nofork –nopidfile –systemd-activation –syslog-only
ExecReload=/usr/bin/dbus-send –print-reply –system –type=method_call –dest=org.freedesktop.DBus / org.freedesktop.DBus.ReloadConfig
Also starten wir den dbus-daemon von Hand und stellen fest, daß er nicht startet. In dem Fall, weil seine libdbus.so.3 ein Target nicht enthielt, was nur sein kann, wenn die Version des Daemons und der lib nicht zusammen passen.
Ein „rpm -qa | grep dbus | sort “ brachte dann auch gleich den Fehler zutage. Statt 1.11.18 war der dbus-daemon nur als 1.11.16 installiert. Offensichtlich war der Rechner beim Update unsanft gestört worden oder der Updateprozess hing aus irgendeinem anderen Grund. Das kann man ja leicht mit einem Update beheben, oder ? 😉
Wie sich rausstellte, konnte man das nicht, weil für das Update durch RPM der DBUS-Daemon laufen müßte. Nun Starten Sie mal einen Update um den DBUS Daemon zu updaten, weil der nicht startet, weil er die falsche Version hat.
Das Ende naht ?
Hier hätte das Ende der Geschichte sein können, weil zu dem Zeitpunkt auch keine Livedisk vorhanden war, um den Rechner mal sauber zu starten und in einer Chroot dann das ausstehende Update zu applien.
Hey… wir haben doch einen SSH Zugang .. da geht doch auch … SCP 😀 Und wie der Zufall das so wollte, hatten beide Rechner das gleiche OS drauf.
Lösung:
scp /usr/bin/dbus-daemon root@externeipdeszielrechners:/usr/bin/
Dann den dbus von Hand starten und die dbus pakete installieren die noch im DNF-Cache auf der Platte lagen. Das findet man unter /var/cache/dnf/updates…./ Da müßt Ihr ggf. mit find mal nach“.rpm“ suchen. Das Cache kann ziemlich unaufgeräumt sein.
Nun noch sauber den dbus über systemd neugestartet und „dnf update -y“ benutzen um alle ausstehenden Updates einzuspielen. Das wärs dann.
Kleiner Tip: Zwei Shells benutzen, weil der Updateprozess wird gemäß den Anweisungen in den RPMS die Dienste neustarten wollen, was wegen des nicht vorhandenen Systemstarts nicht klappt. d.h. die Hängen alle beim „systemctl start blahblah.service„, was man mit ps auxf leicht sehen kann.
Einfach die Pids von den Starts mit kill abschiessen, wir rebooten danach eh frisch.
Berlin: „2:12 Hey, da passiert was“
Ich: „2:12 Ja, ich hab den Reboot ausgelöst, sollte jetzt starten“
Jetzt sind wir fertig. Der Rechner bootet wieder und mehr als 2 Stunden hat es gedauert, denn natürlich haben wir noch einige andere Dinge probiert 😉 Da die aber nicht zur Lösung geführt haben, war ich mal so frei die Euch zu ersparen 🙂
Genauso wenig hilfreich waren :
Microsoft – Skype Zwangstrennung nach 1 Stunde reden .. args!
DTAG – DSL Zwangstrennung mitten im Debug ! Das kann man sowas von gebrauchen wenn man einen Notfall hat!
SystemD – mangels Fehlermeldung, daß DBUS nicht gestartet werden konnte ! Das hätte die Suche ja nur um knapp 90 Minuten verkürzt! Dafür wird noch jemand bezahlen … muharharhar …