Keine Ahnung was ich mir dabei gedacht habe, aber irgendwie war ich der irrigen Meinung, deutsche Behörden in Form von Datenschutzbehörde und Staatsanwaltschaft würden die Datenschutzinteressen der EU-Bürger umsetzen. Das es nicht so einfach werden würde, hätte ich mir nach meiner Behördensafari zur SSLv3 Panne bei der Kripo Leipzig 2017 eigentlich denken können, nein, denken müssen! Alles fing mit einer Linux am Dienstag Nachbesprechung an …
Die Behörden und der Passierschein A38
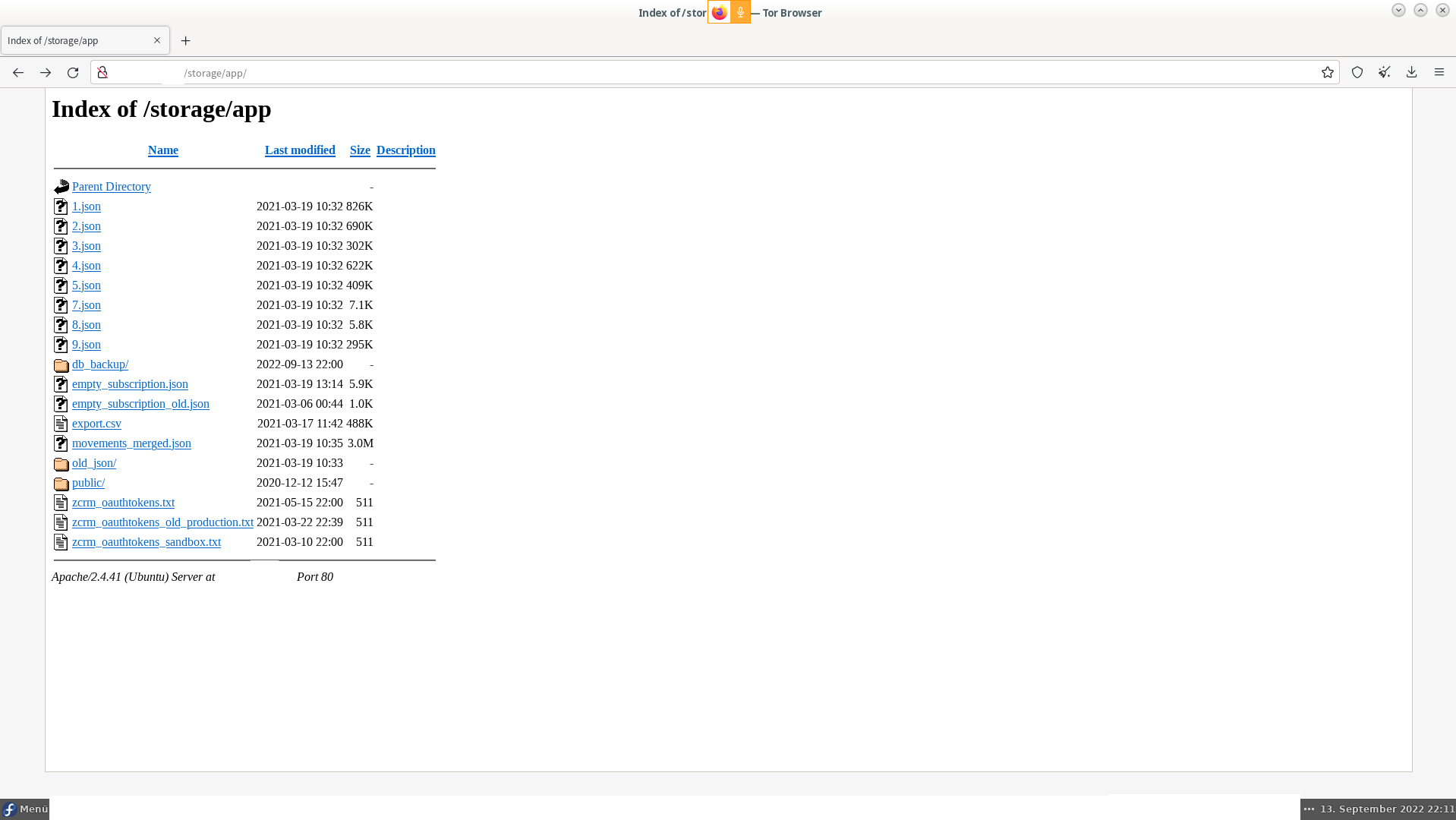
Wir schreiben den 13. September 2022. Es ist ein Dienstag und damit fand abends, wie jede Woche, die Videokonferenz zu Linux am Dienstag statt. Da wir zufällig auf Webserverthemen gekommen waren und wie man da mal nachforscht, was die Angreifer tun, haben sich Matthias und ich nach dem Ende der Zusammenkunft noch ein bisschen in unseren Webserverlogs umgesehen. Dabei viel mir ein Zugriff auf eine Datei namens „datenbank.sql.tgz“ auf, welches auf dem Server todsicher nicht gab. Das bewies auch das Webserverlogfile mit einer 404 Antwort auf die Anfrage. Hacker machen das auf blauen Dunst gern mal, wenn Sie auf anderen Server solche Dateien finden. Es könnte ja noch mehr Unvorsichtige geben da draußen. Damit man als Admin auf dem Laufenden ist, was solche Versuche betrifft, schaut man gelegentlich mal in die Logs.
Während ich noch die Anzahl und Varianten der Anfrage in den Logs ermittelte, suchte Matthias schon bei Google, wer denn so blöd war und solche Dateien öffentlich indizierbar rumliegen lies … und wurde prompt fündig 🙂 Ein Server, der mal irgendwann eine Webseite werden wollte, lieferte uns unter seiner IP direkt alles, was das Herz eines Datendiebs höher schlagen lässt: frei zugängliche Backupfiles der Datenbank seit ~2020. Aber das war nicht alles, da gab es doch noch das „Parent“ Verzeichnis.. ohhh… Tokens.. zu Webdiensten… Rootzugänge zur Datenbank .. Passwörter für das CRM System bei ZOHO und eine Datei namens „export.csv“ und die hatte es in sich: Die Goldader!
Bares Gold funkelte uns da entgegen, wenn man Datendieb war und im Darkweb fremde Daten verkaufen wollte. Ein Dump der Kundendatenbank mit u.a. Vorname, Nachname, Geschlecht, Geburtstagsdatum, Emailadresse, Mobilfunknummer und alles, was man so an Schönheitsbehandlungen bei der entsprechend verantwortlichen Firma so gebucht hatte, nebst Beträgen und anderen Daten, die wir aufgrund mangelnder Italienisch Kenntnisse nicht direkt zuordnen konnten. Ein kurzer Check bei „‚;– have i been pwned?“ später war klar, daß einige der Kunden auch schon bei Facebook und anderen Leaks Daten verloren hatten, aber einige waren „ohne Befund“. Jetzt waren das nur knapp 3.500 Datensätze und damit kein echtes Spektakel wert…. aber es sollte anders kommen!
Der Skandal sind nicht die paar Datensätze
Die teils eklatanten Sicherheitsmängel bei eingesetzter Software und Konfiguration des Server lassen wir jetzt mal beiseite, dies sind Sachen, welche die LDA Bayern zu interessieren haben. Nur soviel, deren Hauptwebseite läuft noch PHP 5.6 und einem WordPress 4.x, was beides schon vor 2018 veraltet war. (Aktuell: PHP 8.2 und WP 6.0.2)
Am Mittwoch habe ich dann morgens die Kripo im Braunschweig informiert, die auch im Rahmen der Möglichkeiten geholfen hat. Es liegt nämlich keine durch die Polizei verfolgbare Straftat vor, auch wenn „Verleitung zu einer Straftat“ meiner laienhaften Meinung nach durchaus gegeben ist, weil ja jeder der bei Google sucht, diese Daten ohne weiteres runterladen und missbrauchen kann.
Daher rief die Kripo bei Hetzner in Nürnberg an und erfuhr dort in der Rechtsabteilung eine knallharte Abfuhr: man sollte doch das ABUSE Formular von Hetzner nutzen, die Rechtsabteilung könnte da nichts an die Admin weiterleiten. Merkt Euch mal, daß die Kripo die Rechtsabteilung von Hetzner auf dem kurzen Dienstweg am 14.9. informiert hat.
Der Abuse bei Hetzner
Da ich bereits alle Daten für die Landesdatenschutzbehörde in Bayern (LDA Bayern) aufbereitet hatte, habe ich auch das Formular bei Hetzner ausgefüllt. Ein sehr tristes Formular, wie ich erwähnen darf. Dort habe ich erwähnt, daß die Kripo die Rechtsabteilung bereits informiert hat und das es eine Verfahrens-ID bei der LDA gibt. Man darf also mit einer Anfrage der LDA rechnen. Das ganze war natürlich mit Beweisen und der Bitte um Abschaffung des Missstandes garniert. Jetzt könnte man meinen, alles getan zu haben und das die Daten zügig aus dem Netz entschwinden werden. Weit gefehlt!
Es vergingen also die Tage und nichts passierte
Natürlich habe ich jeden Tag die Webseite per Tor besucht um zu prüfen, ob die Daten noch da sind. Tor ist eine nützliche Hilfe, wenn man bei solchen Verfahren nicht ins Visier von mit Maschinenpistolen bewaffneten Abseilfans kommen möchte, da einige Staatsanwaltschaften auch schon mal Täter- und Zeugen-IPs verwechseln 🙂
Die Reaktion der Staatsanwaltschaft Nürnberg-Fürth
Am Samstag den 17.09. habe ich der Staatsanwaltschaft in Nürnberg-Fürth eine Handlungsaufforderung per Email geschickt, in der alles erklärt wurde und unter Berufung auf §13 StGB ( Begehen durch Unterlassen ) erklärt wurde, daß Hetzner ja informiert wurde, aber nicht handelte, obwohl es Ihnen möglich war, was jetzt klar ein §13 Fall wäre. Da kommen hilfweise noch die Beziehung zwischen Hetzner und dem Webseitenbetreiber durch §28 DSGVO und die Allgemeine Schadensersatzpflicht nach §823 BGB ins Spiel.
Kurz erklärt:
§28 DSGVO regelt das Verhältnis zwischen Datenverarbeiter, hier Hetzner als Hoster, und dem Datenschutzverantwortlichen aka. dem Kunden. Da ist eine Pflicht enthalten, daß der Auftragsdatenverarbeiter den Kunden über Missstände informiert und an der Beseitigung mitwirkt.
§823 BGB regelt, daß wenn jemand den Schaden von einem Dritten ( hier die betroffenen Kunden des Serverkunden ) abwenden kann, er dies zu tun hat, ansonsten wäre er schadensersatzpflichtig. Juristen mögen mir die starke Vereinfachung verzeihen 😉
Daraus ergibt sich meiner Meinung nach, daß §13 StGB auf Hetzner zutrifft, denn sie sind informiert und in der Lage den Schaden leicht abzuwenden. Die brauchen nur den Server kurz vom Netz nehmen. Dauert vielleicht eine Minute 😉
Auch das Schreiben an die Staatsanwaltschaft verpuffte ohne Wirkung.
Die Landesdatenschutzbehörde Bayern
Am Donnerstag, den 22.09. habe ich mit der LDA Bayern telefoniert, die mir mitteilte, daß die verantwortliche Kollegin bis nächste Woche unerreichbar sei. Mein Tipp: Urlaub. Daher sollte ich doch eine Email zur Nachfrage auf die Verfahrens-ID schreiben, weil der Kollege, der das auch machen könnte, heute nicht mehr mit mir telefonieren könne. Also, habe ich eine Email geschickt. Natürlich führte auch dies zu … nichts.
„Michael Ende hat das Nichts in weiser Voraussicht in der Unendlichen Geschichte verarbeitet, er kannte wohl die deutschen Behörden näher.“ ( ein Berliner Kängeroo )
Passierschein A38
Am 27.09, dem Dienstag nach dem Anruf, habe ich dort nochmal angerufen, denn die Kollegin sollte ja wieder da sein. Ratet mal, habe ich mit der gesprochen oder nicht 😉 Ihr ahnt es, „sie ist in einem Meeting, das bis heute Nachmittag dauert.„. „Und was ist mit dem Kollegen von letztem Donnerstag, ist der zu sprechen?“ „Nein, schreiben Sie eine Email….“ .. kommt mir irgendwie bekannt vor 🙁
Ok, da ich schon einmal am Telefon war, rief ich bei der Staatsanwaltschaft an und wollte mal nachfragen, ob denn die Email überhaupt angekommen ist, weil man von denen ja auch nichts gehört hat. Oh mann!
Das nachfolgende Gespräch ist dem Gedächtnis entnommen und könnte abweichend formuliert worden sein, ist aber sicher inhaltlich so abgelaufen:
Telefonzentrale Staatsanwaltschaft Nürnberg-Fürth: „Staatsanwaltschaft … „
Ich: „[Name], ich wollte nachfragen, ob meine Email vom 17.9. 12 Uhr angekommen ist und wenn ja, was da Sachstand ist.“
Telefonzentrale Staatsanwaltschaft Nürnberg-Fürth: „Um welches Aktenzeichen handelt es sich denn?“
Ich: „Keine Ahnung, ich habe ja von Ihnen noch nichts gehört.“
Telefonzentrale Staatsanwaltschaft Nürnberg-Fürth: „ohne Aktenzeichen kann ich Sie nicht Durchstellen.“
( und wie machen Kripobeamte das, wenn die mit dem Staatsanwalt über was neues reden wollen? 🙂 )
Telefonzentrale Staatsanwaltschaft Nürnberg-Fürth: „ich kann Sie nur zum Amtsgericht, dem Landgericht und dem OLG durchstellen. Wohin wollen Sie?“
Ich: „Und was solle ich bei denen? Ich will ja wissen, ob meine Email bei Ihnen ankam“
Telefonzentrale Staatsanwaltschaft Nürnberg-Fürth: „Ohne Aktenzeichen kann ich Sie nur zum Amtsgericht, dem Landgericht und dem OLG durchstellen. Also wohin?“
Ich: „Und was machen wir da jetzt?“ ( Ganz im Stil von Paul Panzer )
Telefonzentrale Staatsanwaltschaft Nürnberg-Fürth: „ich kann Sie zum Amtsgericht, dem Landgericht und dem OLG durchstellen. Wohin wollen Sie?“
Ich: „Dann nehme ich das Amtsgericht“
… es klingelt … nun rauscht es, als wenn das Büro ohne Wände auf dem Mittelstreifen der A2 erbaut wäre..
Telefonzentrale Amtsgericht Nürnberg-Fürth: „Registratur, Hallo?“
Ich: „Es rauscht fürchterlich“
Telefonzentrale Amtsgericht Nürnberg-Fürth: „Ja, das ist das Telefon. Wer war da?“
Ich: „[name] ich wurde von der Telefonzentrale der Staatsanwaltschaft vermittelt. Ich habe vor 10 Tagen eine Email an die Staatsanwaltschaft geschickt und würde gern wissen, ob die ankam, weil nichts passiert ist. „
Telefonzentrale Amtsgericht Nürnberg-Fürth: „Sie sind hier beim Amtsgericht. Sie sind hier falsch.“
Ich: „Das weiß ich, daß haben Sie der Telefonzentrale bei der Staatsanwaltschaft zu verdanken. Wissen Sie denn vielleicht, wo man da richtig wäre?“
.. und ja, der Kollege wußte das. Er versucht zweimal mich zu verbinden, aber keiner ging ran. Dafür habe ich aber die Durchwahl der Wachtmeisterrei von der Staatsanwaltschaft bekommen :)…
… etwas später …
Wachtmeisterrei Staatsanwaltschaft Nürnberg-Fürth: „Staatsanwaltschaft Nürnberg-Fürth [Name] Bitte?“
Ich: „[Name] ich wollte nachfragen, ob meine Email vom 17.9. 12 Uhr angekommen ist und wenn ja, was da jetzt mit ist.“
Wachtmeisterrei Staatsanwaltschaft Nürnberg-Fürth: „Ich verbinde Sie mal“
... mit der Poststelle, wie sich rausstellte …
Ich: „[Name] ich wollte nachfragen, ob meine Email vom 17.9. 12 Uhr angekommen ist und wenn ja, was da jetzt mit ist.“
Poststelle Staatsanwaltschaft Nürnberg-Fürth: „Haben Sie denn ein Aktenzeichen für mich?“
….normalerweise wäre das jetzt eine Endlosschleife geworden aber…
Ich: „Nein, woher denn, es hat ja niemand geantwortet.“
Poststelle Staatsanwaltschaft Nürnberg-Fürth: „Wenn Ihnen noch niemand geantwortet hat, dann liegt die Anzeige noch beim Staatsanwalt.“
Ich: „Das war keine Anzeige, jedenfalls nicht im klassischen Sinne, mehr so eine Aufforderung etwas zu tun.“
Die Dame erklärte dann, wie das da so normalerweise mit der (E)Post abläuft und das 10 Tage doch ein „bisschen knapp wären“ um da schon nachzufragen, aber ich solle doch bitte eine EMail mit der Nachfrage und bitte um Rückmeldung schicken, sie leitet das dann garantiert an den Richtigen weiter. Das habe ich dann gemacht und Euch anschließend diesen Text niedergeschrieben 😀
Das Gespräch mit der Telefonzentrale ist übrigens länger gelaufen als oben beschrieben, denn dort kam es wirklich zu einer Endlosschleife wegen dem nicht-existenten Aktenzeichen 😉
Der Tag danach
Der Tag nach dem Tag danach, und die Tage nach diesem Tag, waren wie die Tage vor dem Tag davor: Nichts neues im Westen. Hätte ich den kleinen Witz mit Michel Ende nicht schon gebracht, jetzt wäre ein Zitat über das sich ausbreitende Nichts angebracht.
Am 21.9. habe ich mich mit der c’t Redaktion besprochen. Die fanden zwar alle Vorwürfe bestätigt, aber der Fisch war leider zu klein um darüber zu berichten, womit die ~3500 Datensätze gemeint waren. Mir ging es aber um die Untätigkeit, da ich denke, daß darin der eigentliche Skandal besteht. Ich, und andere mit denen ich die Infos zum Ablauf besprochen habe, sehen das auch so. D.b. die Erwartungshaltung an unsere Behörden ist offensichtlich in der Bevölkerung deutlich überhöht.
Hinweis: Wir sind jetzt zur Orientierung bereits in Woche 4 der Nichtsausbreitung angekommen.
Am Mittwoch den 5.10. habe ich die von YouTube bekannte Rechtsanwaltskanzlei WBS über Ihr Kontaktformular um deren Meinung zum weiteren Vorgehen per Rückruf gebeten. Da ich eine gute Zusammenfassung schon für die LDA gemacht hatte, habe ich mal meine Datenschutzmeldung hinzugefügt. Herr Solmecke hatte am 3.10 und am 5.10 passende Videos zum Thema eingestellt, was lag also näher? 🙂
Die Zeit verging und Ihr ahnt es schon … bis heute kein Rückruf 🙁 ( <= Stand 7.10. .. wichtig 🙂 )
Am Samstag den 8.10. habe ich bei unserem Rechenzentrum angerufen, ob die vielleicht einen „Kontakt“ bei Hetzner haben, aber leider ist Hetzner die „geschätzte Konkurrenz“ und Kontakte damit, gefühlt, nicht erwünscht 🙂
Das Lebenszeichen
Mein Status wechselte am 10.10.2022 in „bedingt hoffnungsvoll“ als ich folgende Email laß:
Dear Sir or Madam,
We have received your information regarding spam and/or abuse and we shall follow up on this matter.
The person responsible has been sent the following instructions:
– Solve the issue
– Send us a response
– Send you a response
…
Kind regards
XXXXXXX XXXXXX
Hetzner Online GmbH
Wie ich im Anhang nachlesen durfte, ist das (un)stylische WebFormular auch nur ein Frontend für einen Emailversand an die abuse@hetzner.com Adresse, was zwei Dinge nahelegt:
1. die Kategorisierung als „sonstiges“ ( weil nichts andere paßte ) hatte keinen Einfluß auf die Verarbeitungszeit und
2. die sind da echt sehr weit in Rückstand geraten, denn laut Anhang kam die „Email“-Version des Formulars da beim Absenden des Formulars an.
Dienstag, der 11.10.2022
Das Telefon klingelt. Eine Nummer aus Köln. Dummerweise, in einem Augenblick in dem ich nicht in der Nähe war. Ein Check im Web und ich wußte, es war WBS, also Rückruf. Leider kam kein Gespräch mit dem Anrufer zustande, Noch wissen wir nicht, was der- oder diejenige mitteilen wollte.
Ein quälend langsam vergehender Dienstag wäre die Folge gewesen, wenn ich nicht einen Vortrag für Abends hätte schreiben müssen: „SSH: All Inclusive„.
Servern down
Abends stellten wir bei Linux am Dienstag fest, daß der Server nicht mehr erreichbar war. Wer den letztendlich abgeschaltet hat, konnten wir noch nicht in Erfahrung bringen. Am Vortag, als Hetzner mailte, war der Server noch da, es muß also im Laufe des Dienstags passiert sein.
ZIEL ERREICHT
Die Daten sind aus dem Netz verschwunden, was das erklärte Ziel der Aktion war. Danke an alle, die mit geholfen haben. Von den involvierten Behörden habe ich bis heute (12.10.) noch nichts dazu gehört.
Das Letzte(?) Update vom 17.10.2022
WBS.LAW rief mich gerade an, nur um mir mitzuteilen, daß sie noch gar nichts gemacht hatten und erstmal hören wollten, was los ist. D.b. das weiterhin unklar ist, wer Hetzner nach 4 Wochen dazu gebracht hat, dem, Abuse endlich mal nachzugehen, denn bis heute gibt es von den Behörden dazu keine Rückmeldung.
An dieser Stelle breche ich jetzt das Eis und stelle den Bericht ins Netz. Wenn es ab jetzt noch Meldungen dazu gibt, reich ich Euch die ggf. nach.
Nein, war es nicht.. 19.10.2022
Da kam doch jetzt gerade doch noch ein Lebenszeichen von der LDA Bayern rein. Bildet Euch selbst eine Meinung dazu:
Sehr geehrter Herr ……,
wir kommen zurück auf Ihre Eingabe vom 14.09.2022. Nachdem Sie nicht die Verletzung eigener Rechte behauptet und plausibel dargestellt haben, bewerten wir Ihre Eingabe als Kontrollanregung.
Wir möchten Sie zunächst darauf hinweisen, dass wir, das Bayerische Landesamt für Datenschutzaufsicht (BayLDA), die Einhaltung des Datenschutzrechts im nicht-öffentlichen Bereich in Bayern überwachen, d. h. primär in den privaten bayerischen Wirtschaftsunternehmen, Vereinen und Verbänden und bei freiberuflich Tätigen.
In Ihrer Eingabe verweisen Sie jedoch auf eine Sicherheitslücke bei einem italienischen Verantwortlichen. Wir haben Ihre Angaben geprüft und dabei festgestellt, dass wir in dem Fall nicht tätig werden können, da das verantwortliche Unternehmen nicht in unserer Zuständigkeit ist. Zu Recht geben Sie an, dass sich die ungesicherten Backup-Dateien auf einem Server befinden, der gemäß der IP-Adresse bei der Hetzner Online GmbH lokalisiert werden kann. Hierbei, also bei der Hetzner Online GmbH, handelt es sich jedoch datenschutzrechtlich gesehen nicht um den Verantwortlichen, sondern wahrscheinlich lediglich um einen Auftragsverarbeiter, der von dem italienischen Unternehmen eingesetzt wird. Für die Sicherheit der Daten ist zunächst jedoch das verantwortliche Unternehmen zuständig. Dieses Unternehmen muss dafür Sorge tragen, dass personenbezogene Daten ausreichend geschützt sind. Tätig werden muss in dem Fall deshalb auch der Verantwortliche, der die Dateien nicht gesichert hat, und eben nicht der Auftragsverarbeiter.
Wir bitten Sie deshalb sich an den Verantwortlichen, also das italienische Unternehmen, oder aber an die für Sie in Ihrem Bundesland zuständige Datenschutzaufsichtsbehörde zu wenden. Ein Tätigwerden unsererseits ist aufgrund der fehlenden Zuständigkeit nicht möglich. Den Vorgang schließen wir deshalb mit diesem Schreiben ab.
Mit freundlichen Grüßen
…
Bereich 4 – Cybersicherheit und Technischer DatenschutzBayerisches Landesamt für Datenschutzaufsicht
Promenade 18, 91522 Ansbach
Fangfrage: Hmm…wer wird aus Deutschland in Italien bei einer Behörde wohl mehr Erfolg haben: Ich mit deepl.com als Helfer oder eine deutsche Datenschutzbehörde???
Der 24.Oktober 2022
„Bella-Italia“ lässt schön grüßen, die Datenschutzeingabe mit Deepl’s Hilfe ist per Email angekommen und einem Vorgang zugewiesen worden.
Gespannt warten wir auch die nächste Nachricht, denn wenn die ähnlich schnell sind, kann ich jetzt 4 Wochen in Ruhe verreisen 😀