Eye Candy ist immer wieder ein Thema bei Linux, denn man kann es ja auch mal schön haben wollen, statt immer nur Konsole sehen zu müssen 😉
Eins der Must-Haves ist dann wohl Cairo-Dock, daß bei Fedora per DNF nachinstallierbar ist. Zusammen mit Cinnamon und Gnome, sieht das alles dann schon richtig gut aus.
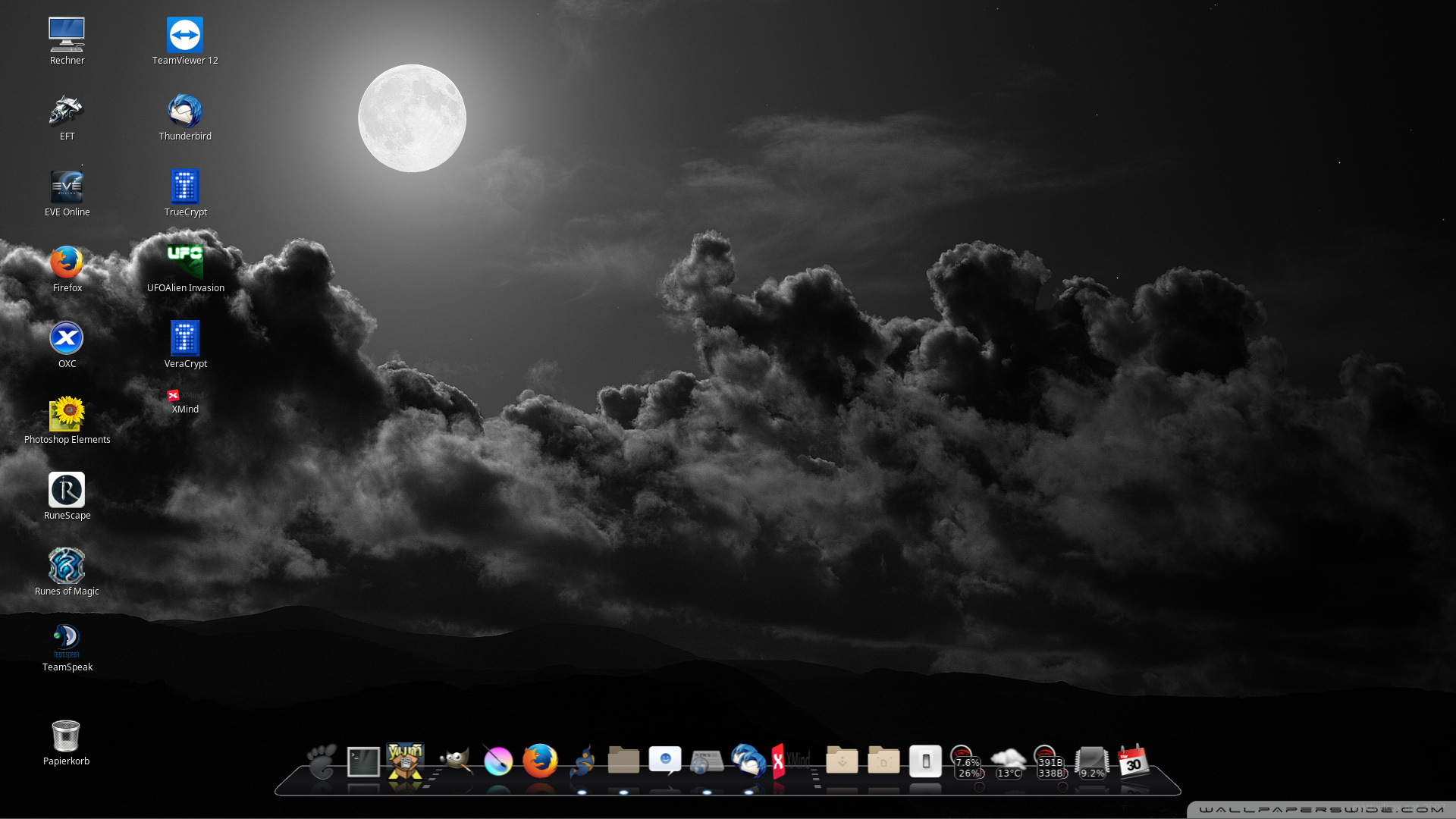
Wer Eye Candy auf seinem Desktop/Laptop bevorzugt , z.B. um Windowsuser blass werden zu lassen, wie cool doch der Nicht-Apple so aussehen könnte 😉 der findet in Cairo den richtigen Partner.
 Cairo-Dock ist nur ein Dock, also kein Windowmanager und damit kann man es unter Gnome-Cinnamon-Xfce usw. einsetzen.
Cairo-Dock ist nur ein Dock, also kein Windowmanager und damit kann man es unter Gnome-Cinnamon-Xfce usw. einsetzen.
Die Vielfalt an Effekten ist erweiterbar, aber auch schon so der Hammer. Was ein bisschen blöd voreingestellt ist, sind die Abmaße des Docks, aber das läßt sich leicht anpassen. Die Konfigurationsoberfläche ist mannigfaltig mit Optionen ausgestattet, so daß man da ganz leicht den Überblick verlieren kann:
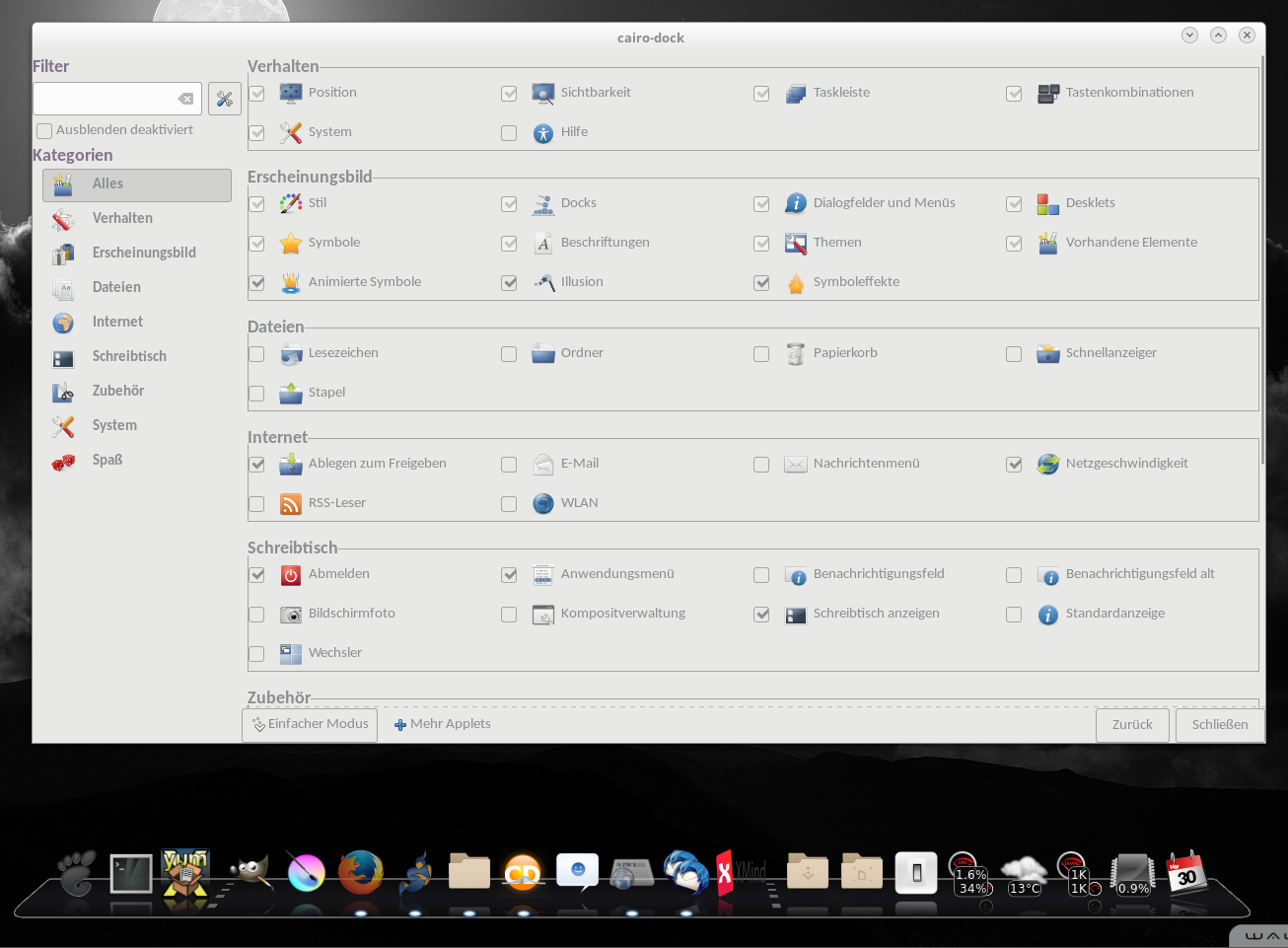 Probleme gibt es eigentlich nur mit der Positionierung, wenn neue Bildschirmkonstellationen zusammen kommen, da zickt es ein bisschen, aber am Ende klappt auch das. Wie man sehen kann, hat jemand vergessen, daß Konfigtool richtig zu layouten, aber wer sieht das schon dauernd 😀 Unter Cinnamon war es einfacher das Dock an die richtige Stelle zu bekommen, als mit Gnome, dafür ist Gnome schneller.
Probleme gibt es eigentlich nur mit der Positionierung, wenn neue Bildschirmkonstellationen zusammen kommen, da zickt es ein bisschen, aber am Ende klappt auch das. Wie man sehen kann, hat jemand vergessen, daß Konfigtool richtig zu layouten, aber wer sieht das schon dauernd 😀 Unter Cinnamon war es einfacher das Dock an die richtige Stelle zu bekommen, als mit Gnome, dafür ist Gnome schneller.
Nachdem ich 2 Stunden lang damit rumgespielt habe, kann ich sagen, daß wenn ich jetzt noch einen Monitor im MacDesign hätte, das wohl bei mir im Dauereinsatz wäre. Wobei der Rechner dann im Foyer stehen würde, hinter Glas, damit den jeder sieht 😉

