Kleines Ratespiel: Wurde für diese Meldung eine SQL-Datenbank benutzt oder nicht? 🙂 Wenig überraschend lautet die Antwort: „Ja“. Das könnte an der weiten Verbreitung und den vielfältigen Anwendungsmöglichkeiten liegen. Es folgt übrigens keine SQL Einführung oder gar ein SQL Lehrgang 😉
Desktop-App: MySQL Workbench 8
Wenn man mit einer SQL-Datenbank arbeiten möchte, braucht man i.d.R. drei Dinge: Einen SQL-Server, einen SQL-Clienten und ein Programm, daß mit den Daten in der SQL-Datenbank etwas machen möchte.
Der im FOSS vermutlich am häufigsten eingesetzt wird, ist MariaDB. Dieser Fork von MySQL entstand, weil Oracle, die die Firma hinter MySQL gekauft hatten, der Meinung war, mal die Regel zu ändern. Das hat einem Teil der Gemeinde, die bislang MySQL mit entwickelt hatten nicht gefallen und so zogen/forkten Sie in eine eigene Trägergesellschaft „The MariaDB Foundation“ um. Zu den größten Sponsoren zählen Booking.com ( die mit den dicken Spamproblem ), Alibaba Cloud und Microsoft (die mit dem eigenen Closed Source MSQL-Server {Wieso eigentlich Microsoft!?!?!?!}), aber auch WordPress Hersteller Automattic, IBM und ein paar Andere.
Bei MariaDB handelt es sich also um den Serverteil, der verschiedene Datenbank Engines unter ein Dach bringt, so daß man diese mit dem SQL-Clienten der Wahl ansprechen kann. Im MariaDB Paket ist ein einfacher Kommandozeilen Client namens „mysql“ mit dabei. Ja, der heißt nicht „mariadb“ sondern „mysql“, weil das ein Fork von MySQL ist, der eine möglichst große Rückwärtskompatibilität anstrebt. Mit anderen Worten, für den Endbenutzer sollte sich nichts ändern. Möglich ist das, weil MySQL eine FOSS Entwicklung ist, die jeder clonen und weiterentwicklen kann, solange er sich an die Lizenzregeln hält.
Jetzt mag nicht jeder in der Konsole rumschrauben, auch wenn das nicht wirklich schwierig ist, und möchte vielleicht eine Desktop-Anwendung benutzen. Hier kommt die MySQL Workbench ins Spiel:
 Wenn man das Fedora Paket MariaDB-Server installiert ( dnf install mariadb-server mariadb ), dann kann man direkt mit der Workbench mit der Arbeit anfangen, da der ROOT Zugang zu dem Datenbankserver nicht beschränkt ist. Das ist natürlich auf Dauer eine völlig untragbare Situation, aber irgendwie muß man erstmal in den Datenbankserver rein kommen, um dann dort die Zugangsdaten für den Rootzugang zusetzen 🙂 In meinem Beispiel ist das erst einmal kein Problem, da die spätere App auf einem abgesicherten Server neu aufgesetzt wird. Aber sobald Eurer Server übers Netz erreichbar ist, ist ein Passwortschutz unumgänglich.
Wenn man das Fedora Paket MariaDB-Server installiert ( dnf install mariadb-server mariadb ), dann kann man direkt mit der Workbench mit der Arbeit anfangen, da der ROOT Zugang zu dem Datenbankserver nicht beschränkt ist. Das ist natürlich auf Dauer eine völlig untragbare Situation, aber irgendwie muß man erstmal in den Datenbankserver rein kommen, um dann dort die Zugangsdaten für den Rootzugang zusetzen 🙂 In meinem Beispiel ist das erst einmal kein Problem, da die spätere App auf einem abgesicherten Server neu aufgesetzt wird. Aber sobald Eurer Server übers Netz erreichbar ist, ist ein Passwortschutz unumgänglich.
Mein drittes Problem, das welches mit den Daten arbeiten soll, gibts noch nicht, aber das wird dann in PHP oder JAVA geschrieben sein. Beide Sprachen bringen einen kompletten Support für MySQL(und Forks) Datenbankserver mit.
Mit dem SQL-Clienten kann man jetzt die eigentlichen Datenbanken, Tabellen, Views, Indexe und in letzter Konsequenz auch die Datensätze anlegen und bearbeiten:
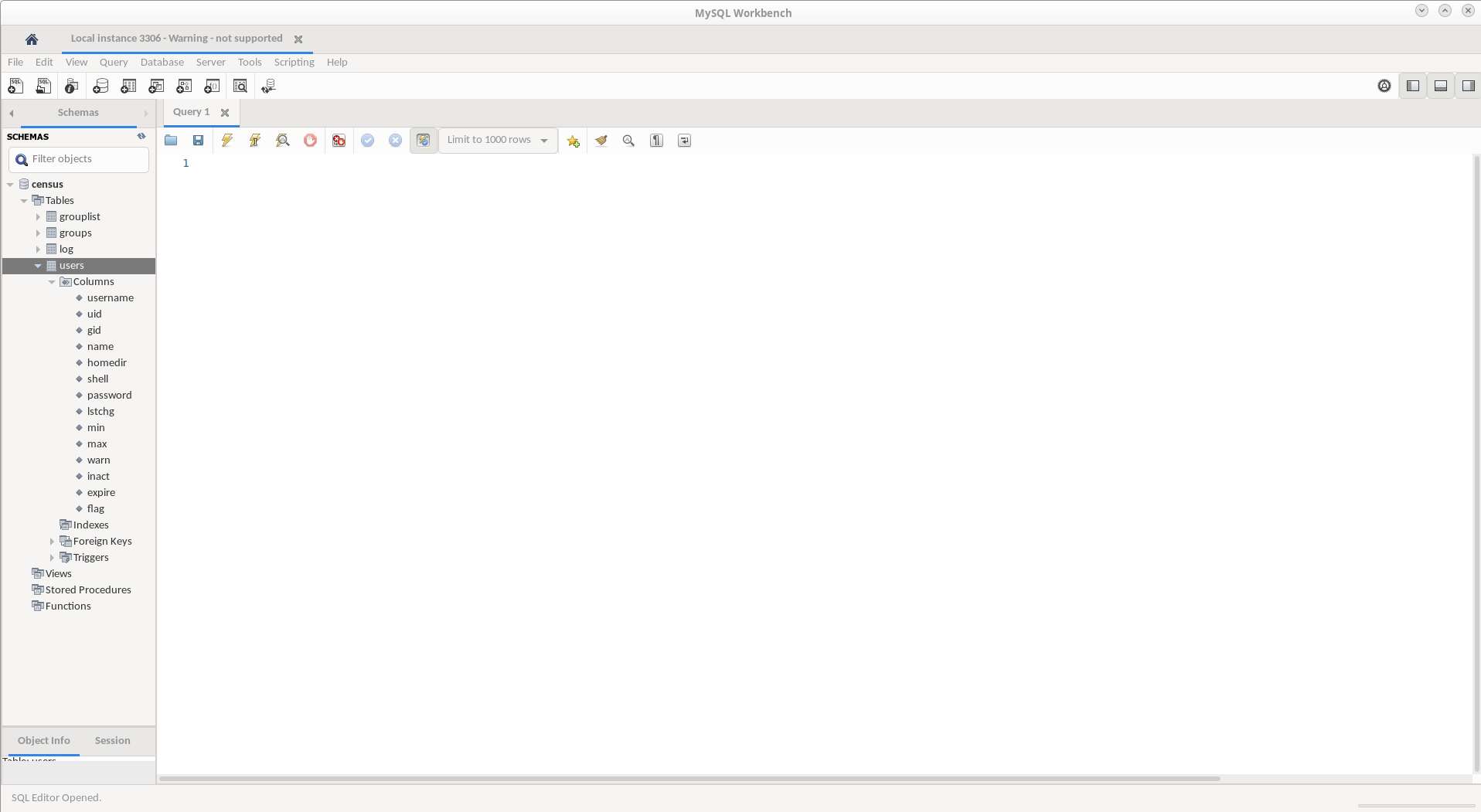 Im Beispiel oben die Datenbank namens „census“ und darin die Datenbanktabelle „users“.
Im Beispiel oben die Datenbank namens „census“ und darin die Datenbanktabelle „users“.
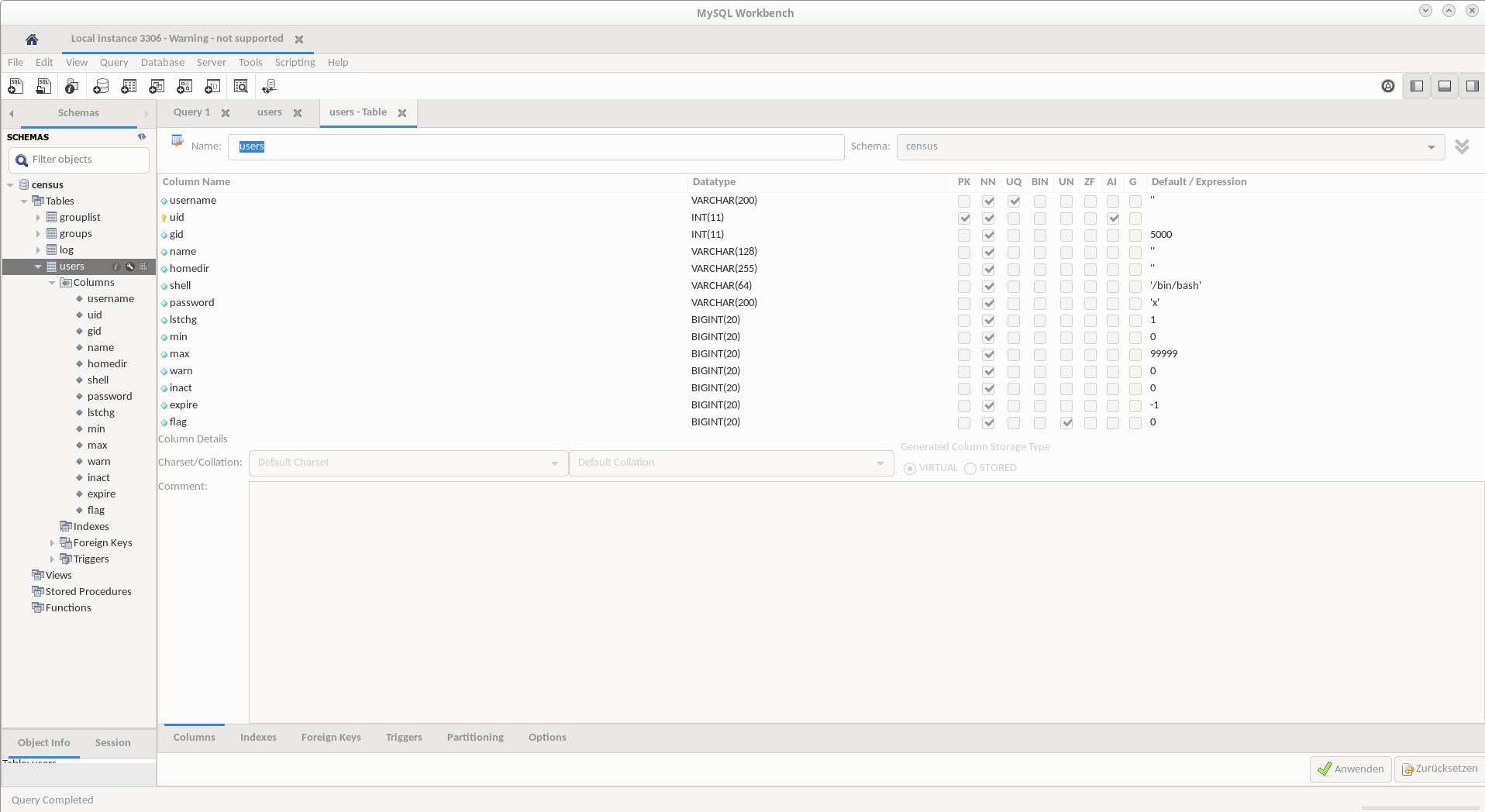 Der eine oder andere könnte an der Tabellenbeschreibung erkennen, um was für ein Projekt es sich handelt, aber laßt Euch sagen, es funktioniert leider nicht sauber…{ PAM_MYSQL Frustanflug niederkämpf}..
Der eine oder andere könnte an der Tabellenbeschreibung erkennen, um was für ein Projekt es sich handelt, aber laßt Euch sagen, es funktioniert leider nicht sauber…{ PAM_MYSQL Frustanflug niederkämpf}..  Wie man hier sehen kann, ist die Ansicht der Datenzeile(n) reicht ansehnlich. Für einfache Bearbeitungen ist der Client gut zu benutzen, aber ehrlich gesagt ist PHPMyAdmin weitaus besser!
Wie man hier sehen kann, ist die Ansicht der Datenzeile(n) reicht ansehnlich. Für einfache Bearbeitungen ist der Client gut zu benutzen, aber ehrlich gesagt ist PHPMyAdmin weitaus besser!
Also wenn Ihr mal ein Desktopprogramm sucht, mit dem Ihr in einer SQL Datenbank arbeiten könnte, das wäre ein brauchbares.
Für Fedora herunterladen könnt Ihr das hier: https://dev.mysql.com/downloads/workbench/#downloads Ihr müßt aber erstmal das passende OS ( hier Fedora ) auswählen, damit Euch die Downloadlinks angeboten werden. Das klappt sogar erfreulicherweise ohne Javascript 🙂 Die Fedora RPM-Pakete gibt es nur für 64Bit Versionen, aber das dürfte einen heutzutage nicht mehr wirklich stören.