Es ist mal wieder Zeit sich die Statistiken anzusehen:
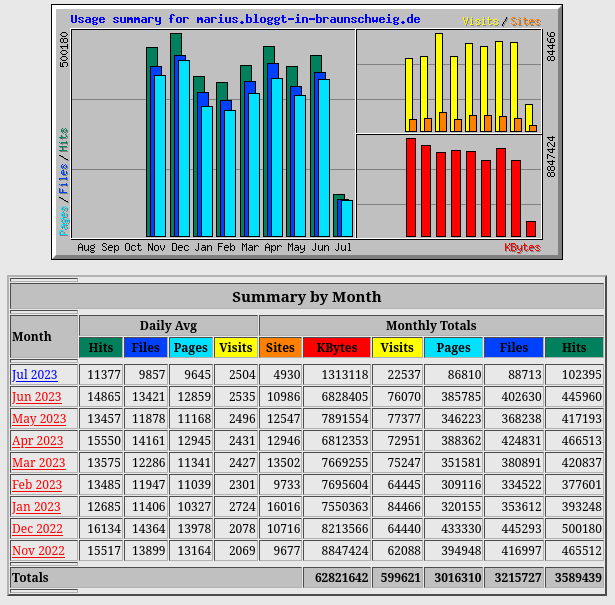
Juli ist natürlich unvollständig..so mitten im Juli 😉
Es bleibt festzustellen, daß, wie jedes Jahr, Januar und Februar schwächeln und die Zahlen ansonsten konstant sind.
Der (IT) Blog aus Braunschweig
Es ist mal wieder Zeit sich die Statistiken anzusehen:
Juli ist natürlich unvollständig..so mitten im Juli 😉
Es bleibt festzustellen, daß, wie jedes Jahr, Januar und Februar schwächeln und die Zahlen ansonsten konstant sind.
Ich habe da mal was für Euch mitgebracht. Für den einen oder anderen Blogger dürfte das interessant sein.
Ihr wißt ja, daß ich vor einigen Wochen mein Blog hinter ein ATS Cache gestellt habe, weil der Seitenaufbau schon langsam wurde. „WordPress“ und die Begriffe „Klein. Schnell. Effektiv“ gehen echt schon lange nicht mehr zusammen 🙁
Da das Cache von sich aus keine vernünftigen Statistiken produzieren kann, die länger als 24h Stunden sind, habe ich im Oktober selbst was gebaut, daß uns diese Daten erzeugt hat. Immer gegen 23:59 wird die tägliche Cache Statistik ausgewertet.
| Datum | Domain | Cached | Uncached |
| 2022-11-01 | marius.bloggt-in-braunschweig.de | 6.891 | 11.800 |
| 2022-11-02 | marius.bloggt-in-braunschweig.de | 6.497 | 12.632 |
| 2022-11-03 | marius.bloggt-in-braunschweig.de | 6.243 | 20.164 |
| 2022-11-04 | marius.bloggt-in-braunschweig.de | 5.101 | 21.138 |
| 2022-11-05 | marius.bloggt-in-braunschweig.de | 4.530 | 21.964 |
| 2022-11-06 | marius.bloggt-in-braunschweig.de | 6.229 | 3.870 |
| 2022-11-07 | marius.bloggt-in-braunschweig.de | 6.006 | 7.245 |
| 2022-11-08 | marius.bloggt-in-braunschweig.de | 6.783 | 15.956 |
| 2022-11-09 | marius.bloggt-in-braunschweig.de | 7.072 | 17.213 |
| 2022-11-10 | marius.bloggt-in-braunschweig.de | 8.555 | 18.834 |
| 2022-11-11 | marius.bloggt-in-braunschweig.de | 8.856 | 9.707 |
| 2022-11-12 | marius.bloggt-in-braunschweig.de | 6.722 | 12.182 |
| 2022-11-13 | marius.bloggt-in-braunschweig.de | 6.307 | 5.880 |
| 2022-11-14 | marius.bloggt-in-braunschweig.de | 6.213 | 9.338 |
| 2022-11-15 | marius.bloggt-in-braunschweig.de | 1.988 | 1.233 |
| 2022-11-16 | marius.bloggt-in-braunschweig.de | 3.814 | 4.008 |
| 2022-11-17 | marius.bloggt-in-braunschweig.de | 5.163 | 3.015 |
| 2022-11-18 | marius.bloggt-in-braunschweig.de | 5.613 | 6.415 |
| 2022-11-19 | marius.bloggt-in-braunschweig.de | 4.932 | 4.733 |
| 2022-11-20 | marius.bloggt-in-braunschweig.de | 5.037 | 5.112 |
| 2022-11-21 | marius.bloggt-in-braunschweig.de | 5.194 | 9.478 |
| 2022-11-22 | marius.bloggt-in-braunschweig.de | 5.941 | 8.449 |
| 2022-11-23 | marius.bloggt-in-braunschweig.de | 5.486 | 4.567 |
| 2022-11-24 | marius.bloggt-in-braunschweig.de | 5.154 | 8.515 |
| 2022-11-25 | marius.bloggt-in-braunschweig.de | 4.997 | 4.073 |
| 2022-11-26 | marius.bloggt-in-braunschweig.de | 4.660 | 4.586 |
| 2022-11-27 | marius.bloggt-in-braunschweig.de | 4.673 | 7.226 |
| 2022-11-28 | marius.bloggt-in-braunschweig.de | 5.061 | 6.082 |
| 2022-11-29 | marius.bloggt-in-braunschweig.de | 5.285 | 8.368 |
| 2022-11-30 | marius.bloggt-in-braunschweig.de | 5.757 | 8.426 |
| Summe November | 452.969 | 170.760 | 282.209 |
Jetzt cached so ein Cache natürlich nicht nur PHP Seiten, sondern alles von CSS, JS über GIF bis TXT und HTML.
d.b. ich hatte keine 452.969 Seitenaufrüfe 🙂 Die genaue Zahl läßt sich nur Ahnen, bzw. dafür müßte man die Webserverlogs vom Blog analysieren.
Hauptproblem
es gibt über 1200 Seiten im Blog, die alle die gleichen CSS Dateien haben, und sich ggf. auch JS, PNGs etc. teilen. Diese 1200 Seiten werden auch regelmäßig aufgerufen, sei es durch Google oder weil Menschen da auf interessante Links geklickt haben, auf der Suche nach Lösungen.
Das liegt daran, daß statische Elemente für alle Seiten gleich sind und gecacht werden, was ja der Sinn der Übung war. Da die in allen Seiten drin sind, tauchen die natürlich auch bei ungecachten Webseitenaufrüfen als „gecacht“ auf. d.b. der Anteil der statischen Randelemente wie Css,JS,Png sind in der gecachten Zahl stark überrepräsentiert, in der Zahl der ungecachten aber praktisch nicht vorhanden.
Da nur stark frequentierte Seiten, wie z.B. die Startseite im Blog oder echt gut laufende Artikel, überhaupt gecacht werden, weil die Cachezeit z.Z. bei 30 Minuten liegt, tauchen die übermäßig in der gecachten Zahl auf und sind in der ungecachten Zahl und mit wenigen Aufrüfen enthalten. (Hinweis: die müssen da auftauchen, weil wenn es nicht im Cache ist, muß es ja einmal min. nachgeladen werden, was ein ungecachter Aufruf ist).
Das führt uns dazu, daß die ungecachte Zahl (in der Liste oben: rechts) hauptsächlich die alten Beiträge beinhaltet und die gecachte Zahl alle statischen Inhalte und hauptsächlich die Startseitenaufrufe beinhaltet.
Jetzt könnte man eine statistische Untersuchen machen und feststellen, daß 9/10 gecachten Aufrüfen auf Grafiken etc. gingen. Meint, ~ 17.000 Aufrufe auf die Startseite bleiben da übrig, der Rest steckt in der ungecachten Zahl.
Für Euch stürze ich mich natürlich in alle Mühen und hab mal die Serverstatistiken bearbeitet. Da das Cache eine eindeutige IP benutzt um auf den Backendserver zuzugreifen, konnte ich alle Zugriffe für November ausfiltern.
Das waren OHNE CSS,javascript,Jpg,Gif,Png : 234.469
Wenn man sich das genauer ansieht, findet man da drin RSS Zugriffe, Suchen nach Tags und Kategorien. Filtern wir die mit aus, bleiben 114.919 reine Seitenaufrufe übrig OHNE die gecachten Startseitenaufrüfe, also fast alles außer „/“ . Wir dürfen annehmen, daß es ein insgesamt mauer November für das Blog war mit ca. 131.000 Abrufen. Da hat das Blog mit knapp 250.000 schon bessere Monate gesehen. Aber, Transparenz bedeutet ja, nicht nur die guten Monate zu zeigen, sondern auch mal weniger gute 😉
Ganz genau bekommt man die Zahlen wegen des Caches nicht mehr zusammen, außer man wertet dauerhaft die Zugrifflogs vom Cache aus, was für eine Statistik Anwendung recht anspruchsvoll sein wird. Vielleicht baue ich da mal was 😉 Ich gehe davon aus, daß der statische Anteil weniger als 9/10 ist, was mehr Seitenzugriffe auf „/“ zur Folge hätte.
Liebe Maskierte,
heute reden wir wieder über Sterbezahlen, einen kleinen Skandal und das RKI und ich befürchte… in Personalunion.
Das uns das RKI als Bevölkerung nicht mehr mit täglichen Sterbefällen belästigen möchte, weil die sich nicht „dynamisch genug entwickeln“ um weiter von täglicher Bedeutung zu sein (siehe RKI Situationsbericht vom 14.9.) , muß ich mich doch wundern, daß andere Länder, nein private Firmen in den USA, da mehr und genauere Informationen bekommen, als das deutsche Volk vom eigenen dafür zuständigen Institut:
Worldometer is run by an international team of developers, researchers, and volunteers with the goal of making world statistics available in a thought-provoking and time relevant format to a wide audience around the world. It is published by a small and independent digital media company based in the United States.
Kleiner Auszug gefällig, was die derzeit Posten? Bitte schön:
Latest News
September 26 (GMT)
Updates
Quelle: https://www.worldometers.info/coronavirus/country/germany/
Deren Quelle ist wiederum der Tagesspiegel, also eine Zeitung, die wiederum berufen sich auf die Landkreise und „andere Quellen“. Eins muß man allerdings sagen, deren Interaktive Sektion ist gar nicht mal so schlecht, wenn man mal von den nicht namentlich genannten Quellen absieht. Es könnte also viel Fantasie im Spiel sein.
Geht es nach denen, dann sterben in Nordrhein-Westfahlen derzeit täglich 3-4 Menschen in Zusammenhang mit Covid-19, womit sie treibende Kraft für die Gesamtstatistik wären, denn der Rest der Republik hat Null-Linie. Man siehts ja hier:
 Wenn Ihr die Zahlen oben von Wordometer mit dem Graphen über diesem Satz vergleicht, Wird Euch auffallen, daß es keine Spitzen gibt, die aber bei 17 Toten am Tag sichtbar werden müßten. Fairerweise muß ich anmerken, daß mein Graph geglättet ist, weil wir ja nicht mehr die Tageszahlen vom RKI bekommen, sondern nur die Wochenzahlen.
Wenn Ihr die Zahlen oben von Wordometer mit dem Graphen über diesem Satz vergleicht, Wird Euch auffallen, daß es keine Spitzen gibt, die aber bei 17 Toten am Tag sichtbar werden müßten. Fairerweise muß ich anmerken, daß mein Graph geglättet ist, weil wir ja nicht mehr die Tageszahlen vom RKI bekommen, sondern nur die Wochenzahlen.
Jetzt stellt sich die Frage, was stimmt denn nun? Das „keine dynamische Entwicklung“ vom RKI oder die Zahlen vom „Tagesspiegel“, die ja eine Dynamik in Nordrhein-Westfahlen zeigen?
Gemeinsam haben beide Quellen nur eins: Sie geben Zahlen wieder, die im täglichen Grundrauschen an Verstorbenen in der Bundesrepublik untergehen. Der Durchschnitt liegt um die 2.400 Personen am Tag. Solange der Durchschnitt sich nicht signifikant bewegt, ist bevölkerungsweit betrachtet auch nichts schlimmes passiert.
Von einer gefährlichen Welle kann man also nur sprechen, wenn man lediglich Infizierte im Blick hat, aber nicht Erkrankte. Meiner Meinung nach, ist aber die Zahl der Erkrankten ist entscheidend, nicht die der Infizierten.
Vor ein paar Tagen fiel mir dieser Satz im RKI Situationsbericht auf:
Aufgrund der geringen Zahl eingesandter Proben ist keine robuste Einschätzung zu den derzeit eventuell noch zirkulierenden Viren möglich. Seit der 16. KW 2020 gab es in den Sentinelproben keine Nachweise von SARS-CoV-2 mehr.
Sentinelproben kommen aus rund 100 Allgemeinen Arztpraxen, die pro Woche 3 Proben von Patienten mit grippeähnlichen Symptomen an die Arbeitsgruppe Influenza schicken, die dann auf alle Viren und Bakterien getestet werden. Damit erhält man einen Überblick, was alles so im Umlauf ist. Die RKI-FAQ schreibt dazu:
Da momentan ein vergleichsweise kleiner Teil der Menschen hierzulande mit SARS-CoV-2 infiziert ist, ist die Wahrscheinlichkeit gering, dass ausgerechnet in diesen ca. 100 Sentinelpraxen der AGI ein Patient beprobt wird, der sich mit SARS-CoV-2 infiziert hat. Nur in der Hochphase von COVID-19 im März und April gab es in diesem Rahmen einige wenige Patienten, in deren Atemwegsprobe mit SARS-CoV-2 nachgewiesen werden konnte.
Mit einer weiteren Verbreitung von SARS-CoV-2 in der Bevölkerung steigt auch die Wahrscheinlichkeit, dass SARS-CoV-2 wieder in einer Patientenprobe aus einer der AGI-Sentinelpraxen nachgewiesen wird. (Quelle: www.rki.de/SharedDocs)
Jetzt haben wir ja wieder Werte wie in März und April, also habe ich da mal ans RKI geschrieben, ob denn da schon was gesichtet wurde, dies ist die Antwort:
vielen Dank für Ihre Anfrage. Entsprechende Virus-Nachweise werden in den Wochenberichten kommuniziert, siehe https://influenza.rki.de zu 2) die Zahl sollte konstant bleiben oder leicht steigen.
Tja, im Wochenbericht steht aber nix. „2)“ war die Frage, ob geplant ist dieses sinnvolle Netz an Arztpraxen ein bisschen auszubauen, weil 100 sind ja dann doch nicht gerade viele.
Infektionszahlen wie in KW 16 und keine positiven Sentinelproben. Wenn die Zahlen weiter steigen, aber die Proben weiter negativ bleiben, hatten die 300 Arztpraxenpatienten von denen die Proben stammen entweder sehr viel Glück, oder die Frage „Was messen wir da eigentlich?“ müßte mal genau nachgegangen werden.
Es darf angenommen werden, daß derzeit das Dunkelfeld, also diejenigen, die nicht an dem Virus erkranken, ausgeleuchtet wird, weil irgendwen müssen die 1.2 Millionen Tests pro Woche ja prüfen.
Jetzt heißt der Beitrag ja nicht umsonst „The Walking Dead“, denn die sind es, die uns bei den Zahlen fehlen. In KW 16 war der Peak mit ~266 Toten am Tag und das bei ~2.500 Neuinfizierten am Tag. Seit Wochen haben wir tausende von Neuinfizierten am Tag, aber praktisch keine Toten. Ich hatte ja in einer Hochrechnung vorgerechnet, daß uns noch ~7.600 Tote für diese „Grippe“-Welle fehlen. So gesehen, wandeln die Toten tatsächlich noch unter uns und sind dabei äußerst erfreut darüber.
Frankreich vermeldet ja derzeit eine massive Welle an Neuinfizierten. Was euch allerdings eher nicht bekannt sein wird, ist der Umstand, daß in Frankreich, im Gegensatz zu Spanien, derzeit weniger Menschen sterben als im Schnitt der letzten Jahre:
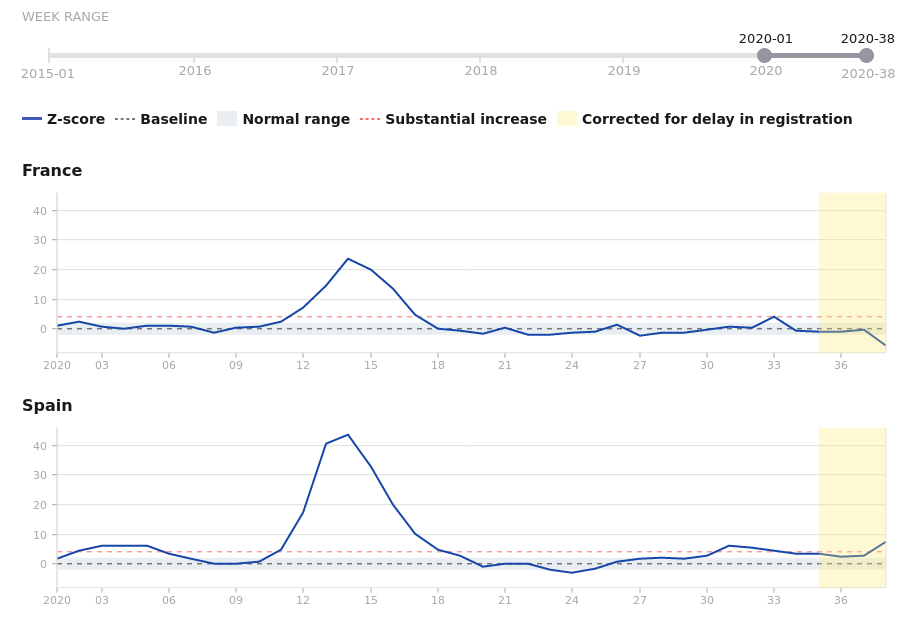
(C) EuroMOMO.eu ( rosa/orange Wochen sind noch nicht endgültig )
Spanien hat es echt schlimm erwischt und die bekommen das gar nicht in den Griff. Ein Mangel an Sonneneinstrahlung kann man da auch nicht als Entschuldigung gelten lassen ( Stichwort Vitamin D ), also was zum Geier machen die da falsch?
Die Franzosen haben damit scheinbar das gleiche Phänomen am Laufen, wie wir: Rudelweise Neuinfizierte, keine Toten. Also auch gilt:
