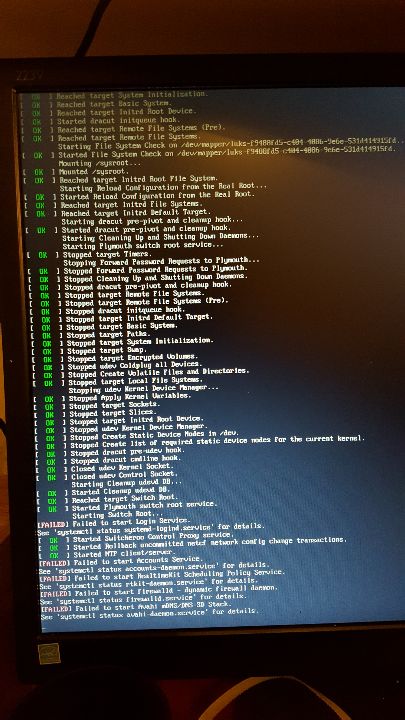
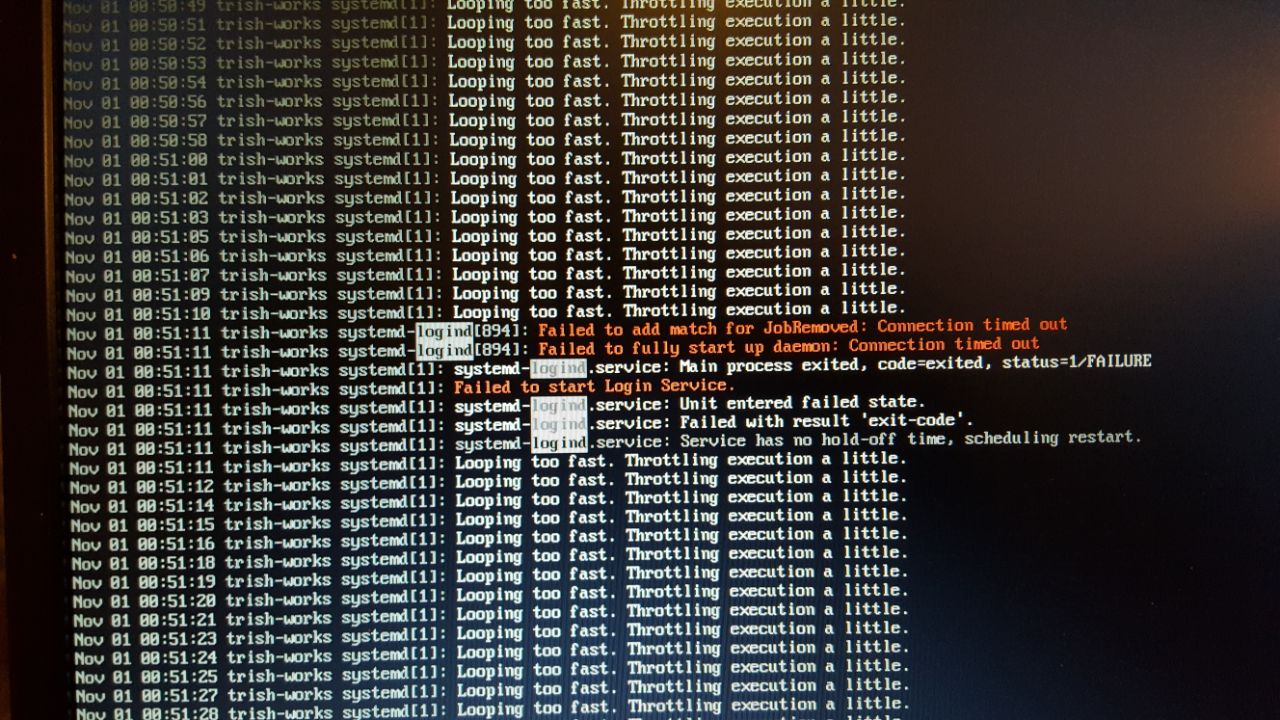
Wie Ihr ( und .tux. ) im letzten Bericht zu selinux-policy lesen konntet, wurde das SEL Problem mit einem generellen Downgrade erstmal behoben. Heute schauen wir uns an, wie man das trotz aller Gegenwehr von Red Hat wieder auf den letzten aktuellen Stand geupdated bekommt 😉
Fedora und die Repostrukturen
Wenn man dnf downgrade benutzt, bekommt man nicht automatisch die letzte Version von einem Paket installiert, sondern nur die nächst kleinste im Repository (Repo) und genau da happerts meiner Meinung nach bei Fedora und Red Hat. Man sollte ja annehmen, daß die aktuelle Version und die vorherige Version eines Paketes zur Verfügung stehen, tun Sie aber nicht. Fedora betreibt ein Basis Repo und ein Updates Repo. Eine funktionierende alte Fassung liegt im Basis Repo, die aktuellste im Updates Repo. Zwischenversionen gibt es leider keine und das ist, denke ich, ein Fehler von Seiten der Distribution.
Immer wieder Koji
Und wieder ist es Koji, die Buildverwaltung für Fedora, die uns bei der Sache als nützliche Datenquelle dient:
https://koji.fedoraproject.org/koji/buildinfo?buildID=1076199
Dort holen wir uns die nötigen RPMs für die lokale Installation:
https://kojipkgs.fedoraproject.org//packages/selinux-policy/3.13.1/283.34.fc27/noarch/selinux-policy-targeted-3.13.1-283.34.fc27.noarch.rpm
https://kojipkgs.fedoraproject.org//packages/selinux-policy/3.13.1/283.34.fc27/noarch/selinux-policy-devel-3.13.1-283.34.fc27.noarch.rpm
https://kojipkgs.fedoraproject.org//packages/selinux-policy/3.13.1/283.34.fc27/noarch/selinux-policy-doc-3.13.1-283.34.fc27.noarch.rpm
https://kojipkgs.fedoraproject.org//packages/selinux-policy/3.13.1/283.34.fc27/noarch/selinux-policy-3.13.1-283.34.fc27.noarch.rpm
Wer meiner Anweisung gefolgt ist, und in die dnf.conf eine Sperre für das Paket eingetragen hat, muß diese Sperre jetzt natürlich wieder entfernen, bevor er das Update durchführen kann.
Manuelles DNF Update
Der Befehl „dnf update ./selinux-policy-*“ ist unser Freund:
[root]# dnf update ./selinux-policy-* Letzte Prüfung auf abgelaufene Metadaten: vor 0:24:25 am Di 10 Jul 2018 09:59:33 CEST. Abhängigkeiten sind aufgelöst. ================================================================================================================================================================================================================================================================================ Paket Arch Version Paketquelle Größe ================================================================================================================================================================================================================================================================================ Aktualisieren: selinux-policy noarch 3.13.1-283.34.fc27 @commandline 541 k selinux-policy-devel noarch 3.13.1-283.34.fc27 @commandline 1.4 M selinux-policy-doc noarch 3.13.1-283.34.fc27 @commandline 2.7 M selinux-policy-targeted noarch 3.13.1-283.34.fc27 @commandline 10 M Transaktionsübersicht ================================================================================================================================================================================================================================================================================ Aktualisieren 4 Pakete Gesamtgröße: 15 M Ist dies in Ordnung? [j/N]:j Pakete werden heruntergeladen: Transaktionsüberprüfung wird ausgeführt Transaktionsprüfung war erfolgreich. Transaktion wird getestet Transaktionstest war erfolgreich. Transaktion wird ausgeführt Vorbereitung läuft : 1/1 Aktualisieren : selinux-policy-3.13.1-283.34.fc27.noarch 1/8 Ausgeführtes Scriptlet: selinux-policy-3.13.1-283.34.fc27.noarch 1/8 Ausgeführtes Scriptlet: selinux-policy-targeted-3.13.1-283.34.fc27.noarch 2/8 Aktualisieren : selinux-policy-targeted-3.13.1-283.34.fc27.noarch 2/8 Ausgeführtes Scriptlet: selinux-policy-targeted-3.13.1-283.34.fc27.noarch 2/8 Aktualisieren : selinux-policy-doc-3.13.1-283.34.fc27.noarch 3/8 Aktualisieren : selinux-policy-devel-3.13.1-283.34.fc27.noarch 4/8 Ausgeführtes Scriptlet: selinux-policy-devel-3.13.1-283.34.fc27.noarch 4/8 Aufräumen : selinux-policy-devel-3.13.1-283.14.fc27.noarch 5/8 Aufräumen : selinux-policy-doc-3.13.1-283.14.fc27.noarch 6/8 Aufräumen : selinux-policy-targeted-3.13.1-283.14.fc27.noarch 7/8 Ausgeführtes Scriptlet: selinux-policy-targeted-3.13.1-283.14.fc27.noarch 7/8 Aufräumen : selinux-policy-3.13.1-283.14.fc27.noarch 8/8 Ausgeführtes Scriptlet: selinux-policy-3.13.1-283.14.fc27.noarch 8/8 Running as unit: run-ra699effd01cd4ceba2ad927e7889ce3b.service Running as unit: run-r27b6453c4a5e4d2ab971a1766a434a30.service Überprüfung läuft : selinux-policy-3.13.1-283.34.fc27.noarch 1/8 Überprüfung läuft : selinux-policy-targeted-3.13.1-283.34.fc27.noarch 2/8 Überprüfung läuft : selinux-policy-doc-3.13.1-283.34.fc27.noarch 3/8 Überprüfung läuft : selinux-policy-devel-3.13.1-283.34.fc27.noarch 4/8 Überprüfung läuft : selinux-policy-targeted-3.13.1-283.14.fc27.noarch 5/8 Überprüfung läuft : selinux-policy-3.13.1-283.14.fc27.noarch 6/8 Überprüfung läuft : selinux-policy-devel-3.13.1-283.14.fc27.noarch 7/8 Überprüfung läuft : selinux-policy-doc-3.13.1-283.14.fc27.noarch 8/8 Aktualisiert: selinux-policy.noarch 3.13.1-283.34.fc27 selinux-policy-devel.noarch 3.13.1-283.34.fc27 selinux-policy-doc.noarch 3.13.1-283.34.fc27 selinux-policy-targeted.noarch 3.13.1-283.34.fc27 Fertig.
Nicht vergessen die dnf.conf wieder mit einer Sperre zu versehen :
# cat /etc/dnf/dnf.conf
[main]
gpgcheck=1
installonly_limit=3
clean_requirements_on_remove=True
exclude=selinux-pol*
Damit wären wir jetzt auf dem Stand, vor dem defekten Paket und bekommen erstmal keine Updates mehr für die selinux-policies.
Ob das so clever war, die automatischen Tests zu umgehen?Wenn ich der Darstellung im Buildsystem glauben darf, dann wurde für den Push Tests umgangen. Da es nachweislich in die Hose gegangen ist, ist das wohl keine gute Idee. Wissen eigentlich alle was diese Policies so machen ?mit dem Befehl „rpm -qi selinux-policy“ bekommen wir eine Beschreibung des Pakets. Leider ist die in diesem Fall äußerst schmal geraten: „SELinux Base package for SELinux Reference Policy – modular. |  |
Daher schauen wir doch mal in ein solches Paket rein. Jetzt ist selinux-policy kein sehr nützliches Beispiel, es setzt nämlich lediglich die System-Konfiguration und andere Metainfos. Viel spannender ist das selinux-policy-targeted Paket, daß die eigentlichen Regeln enthält. U.a. finden wir dies File darin:
/usr/share/selinux/targeted/default/active/modules/100/gnome/cil
Wenn man sich das jetzt mit less ansieht, sieht man nichts, da es bzip2 komprimiert ist. Daher brauchen wir jetzt das hier:
bzless /usr/share/selinux/targeted/default/active/modules/100/gnome/cil
u.A. findet man dann dort die Beschreibungen welche Dateien welche SEL-Contexte haben sollen:
(Die Liste ist nicht vollständig und nur für die eine Gnome Klasse)
…
(filecon „/var/run/user/[^/]*/\.orc(/.*)?“ any (system_u object_r gstreamer_home_t ((s0) (s0))))
(filecon „/var/run/user/[^/]*/dconf(/.*)?“ any (system_u object_r config_home_t ((s0) (s0))))
(filecon „/var/run/user/[^/]*/keyring.*“ any (system_u object_r gkeyringd_tmp_t ((s0) (s0))))
(filecon „/root/\.cache(/.*)?“ any (system_u object_r cache_home_t ((s0) (s0))))
(filecon „/root/\.color/icc(/.*)?“ any (system_u object_r icc_data_home_t ((s0) (s0))))
(filecon „/root/\.config(/.*)?“ any (system_u object_r config_home_t ((s0) (s0))))
(filecon „/root/\.kde(/.*)?“ any (system_u object_r config_home_t ((s0) (s0))))
(filecon „/root/\.gconf(d)?(/.*)?“ any (system_u object_r gconf_home_t ((s0) (s0))))
(filecon „/root/\.dbus(/.*)?“ any (system_u object_r dbus_home_t ((s0) (s0))))
(filecon „/root/\.gnome2(/.*)?“ any (system_u object_r gnome_home_t ((s0) (s0))))
(filecon „/root/\.gnome2/keyrings(/.*)?“ any (system_u object_r gkeyringd_gnome_home_t ((s0) (s0))))
(filecon „/root/\.gstreamer-.*“ any (system_u object_r gstreamer_home_t ((s0) (s0))))
(filecon „/root/\.cache/gstreamer-.*“ any (system_u object_r gstreamer_home_t ((s0) (s0))))
(filecon „/root/\.local.*“ any (system_u object_r gconf_home_t ((s0) (s0))))
(filecon „/root/\.local/share(/.*)?“ any (system_u object_r data_home_t ((s0) (s0))))
(filecon „/root/\.local/share/icc(/.*)?“ any (system_u object_r icc_data_home_t ((s0) (s0))))
(filecon „/root/\.Xdefaults“ any (system_u object_r config_home_t ((s0) (s0))))
(filecon „/root/\.xine(/.*)?“ any (system_u object_r config_home_t ((s0) (s0))))
(filecon „/etc/gconf(/.*)?“ any (system_u object_r gconf_etc_t ((s0) (s0))))
(filecon „/tmp/gconfd-USER/.*“ file (system_u object_r gconf_tmp_t ((s0) (s0))))
(filecon „/usr/share/config(/.*)?“ any (system_u object_r config_usr_t ((s0) (s0))))
(filecon „/usr/bin/gnome-keyring-daemon“ file (system_u object_r gkeyringd_exec_t ((s0) (s0))))
(filecon „/usr/bin/mate-keyring-daemon“ file (system_u object_r gkeyringd_exec_t ((s0) (s0))))
(filecon „/usr/libexec/gconf-defaults-mechanism“ file (system_u object_r gconfdefaultsm_exec_t ((s0) (s0))))
(filecon „/usr/libexec/gnome-system-monitor-mechanism“ file (system_u object_r gnomesystemmm_exec_t ((s0) (s0))))
(filecon „/usr/libexec/kde(3|4)/ksysguardprocesslist_helper“ file (system_u object_r gnomesystemmm_exec_t ((s0) (s0))))
…
und in der findet sich dann kein Hinweis auf den gdm-greeter oder die gnome-session .. Womit es undefiniert ist.
Ich hab versucht da durchzusteigen, aber das ist echt komplex das Zeugs 😉 Vielleicht will ja mal einer ein Diagnosetool dafür bauen, da berichte ich dann gerne drüber.