Ich hatte ja letztes Jahr einen Apache Trafficserver vor das Blog geschaltet, damit die Aufrufzeit des Blogs besser wird. Das hat auch funktioniert, führte aber in den Statstools der Webseite, dazu, daß weniger angezeigt wird, weil weniger im WordPress ankommt.
Blog-Stats seit Einführung des Trafficcache
Schauen wir doch mal rein, was im März 2023 wirklich gewesen ist… 😀
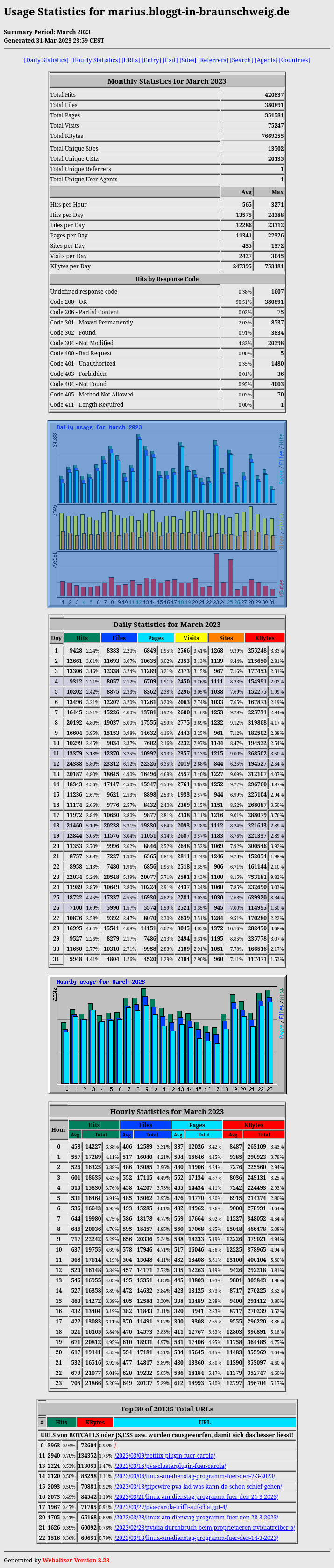 Die Liste mit den TOP 30 URLS habe ich um Seiten wie Javascript, CSS, FEEDS usw. bereinigt. Da die bei allen Seiten beteiligt sind, ist klar, daß die mehr Aufrüfe als die echten Seiten haben. Daher die komischen Positionen in der TOP-Liste 😉 An Platz ein war die XMLRPC, weil die Hacker die mit Forenspam bombardieren 😀
Die Liste mit den TOP 30 URLS habe ich um Seiten wie Javascript, CSS, FEEDS usw. bereinigt. Da die bei allen Seiten beteiligt sind, ist klar, daß die mehr Aufrüfe als die echten Seiten haben. Daher die komischen Positionen in der TOP-Liste 😉 An Platz ein war die XMLRPC, weil die Hacker die mit Forenspam bombardieren 😀
Der Anfang des Jahres ist seit Bestehen des Blogs eher schwach besetzt, was ein Blick in die letzten 6 Monate bestätigt:
 Die Zahlen für April sind logischerweise noch nicht relevant.
Die Zahlen für April sind logischerweise noch nicht relevant.
Falls Ihr auch ein Cache haben wollt
Gibt es da mehrere Möglichkeiten: Ihr geht zu CloudFlare, zu meiner Firma, oder setzt Euch das Cache selbst auf. Letzteres ist eine tolle Kompetenzübung in Sachen Web, weil Ihr alle den Spaß erfahren werdet, den ich auch hatte 🙂 Da Ihr den ganzen Loggingkram dann selbst bauen müßt, könnte das den einen oder anderen überfordern. Ist echt nicht für jeden was. Zum Auswerten habe ich Webalizer nutzen müssen, weil alle anderen noch komplizierter Anzubinden waren oder gar nicht erst funktioniert hätten.
Den Apache Trafficserver könnt Ihr aus dem Fedora Repo bekommen, oder bei apache.org .