Es klingt wie ein schlechter Scherz, aber da hängen Satelliten im All, die helfen, die eigene Position auf cm genau zu bestimmen, und dann landet man in einem Fluß in Leipzig 😉
Pinephone: GPS Ergebnis verbessern
Ihr könnt Euch sicher vorstellen, wo ich wohne. Wenn ich mein Pinephone frage, wo ich denn bin, sagt es mir entweder präzise, daß ich bei mir Zuhause bin, weil es mein WLAN erkennt, oder das ich in einem Fluß bei Leipzig schwimmen bin, im Oktober.
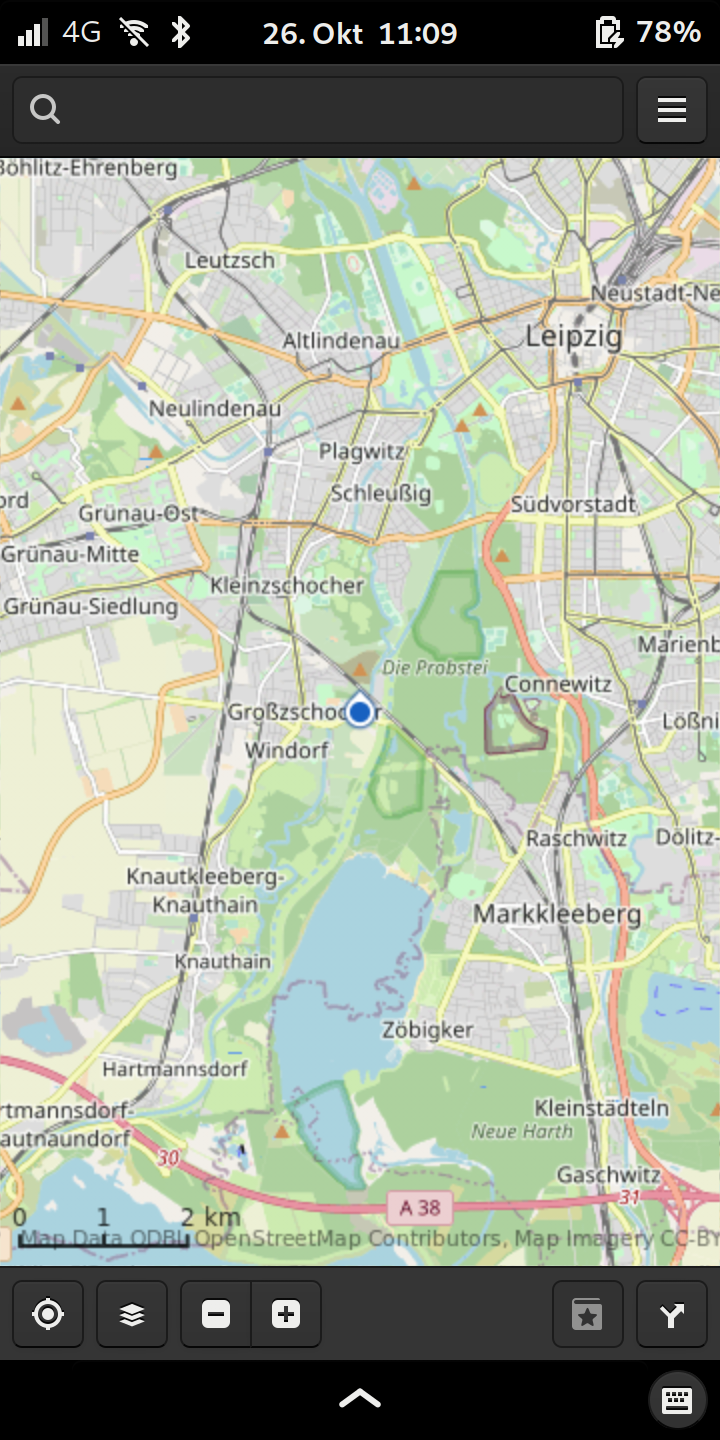 Mit dem Ergebnis kann man natürlich nichts anfangen und bevor jemand über das Pinephone herzieht, Android oder iOS-Geräten ergeht es mit reinem GPS auch nicht anders.
Mit dem Ergebnis kann man natürlich nichts anfangen und bevor jemand über das Pinephone herzieht, Android oder iOS-Geräten ergeht es mit reinem GPS auch nicht anders.
Technisch kann man die Genauigkeit und vor allem die Geschwindigkeit bis zur Fixierung der Position mit Hilfe von vorgefertigten Hilfsdaten deutlich beschleunigen. Die XtraPath Daten werden ins Modem geladen und verbessern da die GPS Verarbeitung. Zunächst muß man diese natürlich erst einmal Laden:
curl -LO http://xtrapath2.izatcloud.net/xtra3gr.bin
Dann müssen wir es Modem zuführen:
mmcli -m any –location-inject-assistance-data=xtra3gr.bin
anschließend noch AGPS aktivieren:
mmcli -m any –location-enable-agps-msb
und dann wären wir auch schon im Geschäft, wenn da nicht die echt schlechte GPS Antenne vom Pinephone wäre. In einem Innenraum nahe am Fenster könnt Ihr GPS vergessen, da schwimme ich immer noch in der Weißen Elster rum.Die Hardware von Samsung ist da besser, die schafft eine Lokalisierung auch dort schon.
Die Genauigkeit bis zum Lock verbessern
Wenn man nicht weiter in Leipzig sein möchte, dann hilft leider nur der naheliegendste Schritt: Der Schritt vor die Tür 😉 GPS funktioniert auf dem Pinephone tatsächlich nur dort, wo man es wirklich braucht: draußen.
Überprüfen könnt Ihr das damit:
mmcli -m any –location-status
Wenn sich die Ausgabe verändert, hat das Pine ein Signal von einem oder mehreren Satelliten aufgefangen. Bleibt die Anzeige eher statisch stehen, wird kein Signal empfangen. Ohne die sich ändernden Signale, kann man die Position nicht bestimmen, da hier die Laufzeiten der Signale benutzt werden und dazu muß man die dauerhaft empfangen.
In dem AGPS RPM, das ich gestern verteilt habe ist ein Script drin, daß Euch das alles beim Systemboot abnimmt: modemmanager-agps-1-1.aarch64.rpm
Da es sich nicht um Fedora spezifische Dinge handelt, könnt Ihr das RPM überall verwenden, wo man mit RPMs arbeitet: RHEL, CentOS, Fedora, YellowDog usw. wichtig wäre nur, daß da auch systemd drauf ist. Sollte das nicht der Fall sein, müßt Ihr Euch wohl ein eigenes Init-Script basteln.
Was uns jetzt noch fehlt
Ok, die GPS Basisfunktionalität ist vorhanden, man bekommt raus, wo man ist. Jetzt brauchen wir noch etwas Komfort in Gnome-Maps z.b. für Live Routing Tracking. Falls das jemand vom Gnome-Projekt mitliest, stellt Euch schon mal auf einen Featurerequest ein 😉
Was weniger schön an GPS ist, es zieht richtig viel Energie aus dem Akku. Laßt es also nicht lange offen, wenn der Akku nicht voll ist. Ein USB-C Ladeadapter für Auto wird in Zukunft eine gute Investition sein.