„Wenn die Hardware versagt,und das Filesystem mit in den Abgrund zieht.“
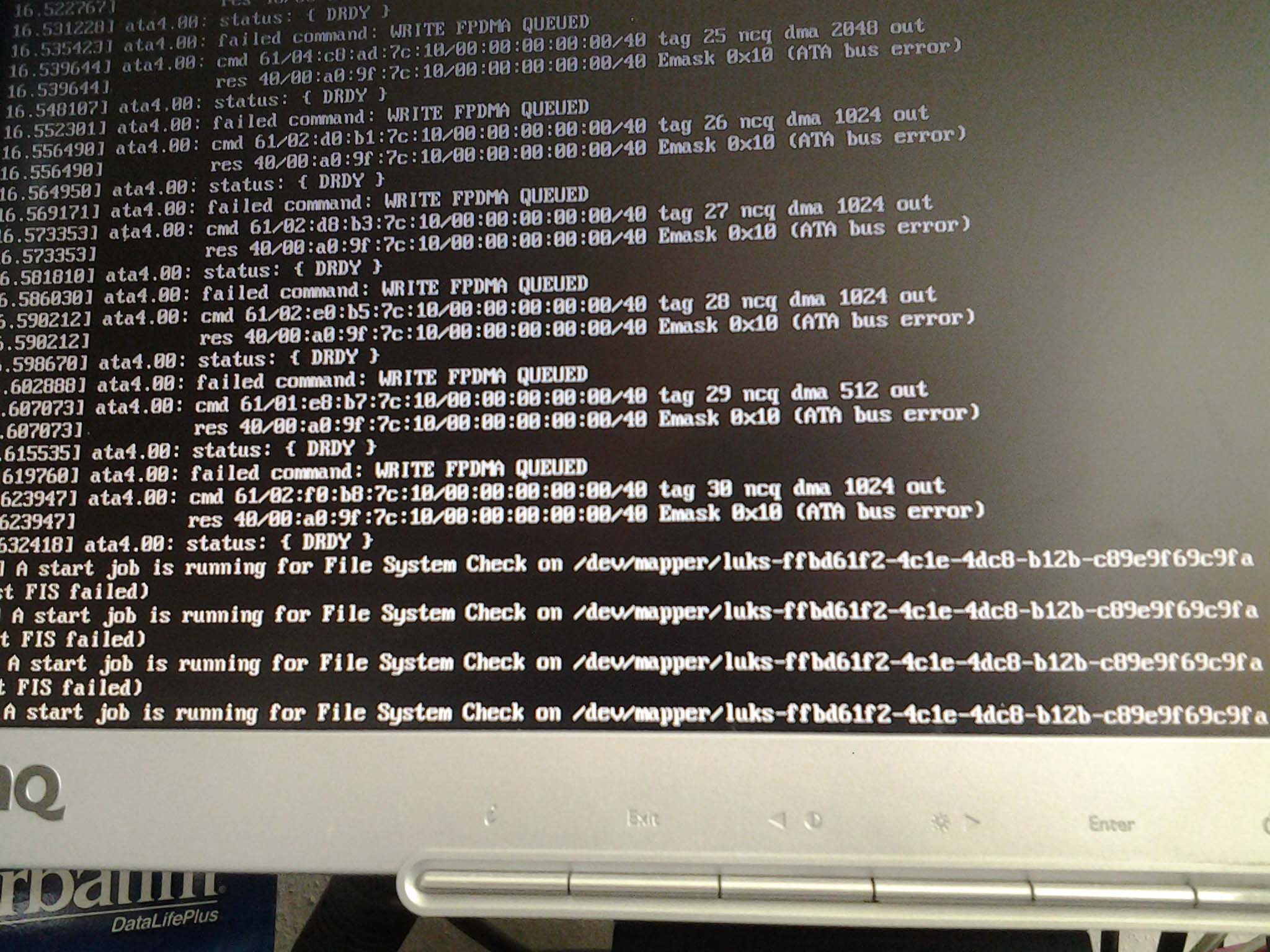
Es war ein lauer Sonntagmittag, der Stream des Chaosradios ergoß sich von Radio Fritz, der Frachter in EVE flog seine Route, als plötzlich … „can’t create tempfile in /tmp/gluster-x34234.tmp“ auf der Konsole erschien. Das Ende vom Lied, die Festplatte hatte versagt:
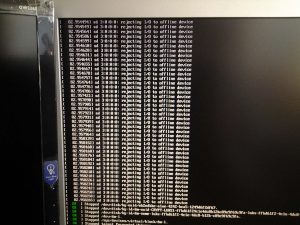
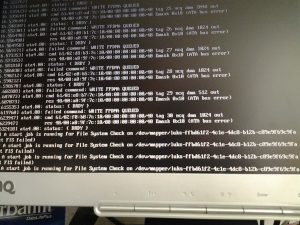
Beim Rebooten startete das System nicht mehr mit dem Hinweis, daß die Superblöcke der Partionen/Filesysteme beschädigt wären.
/var/log/messages-20170402:Apr 2 15:05:32 eve kernel: EXT4-fs (sdc1): filesystem has both journal and inode journals!
/var/log/messages-20170402:Apr 2 15:08:10 eve kernel: EXT4-fs (sdc1): filesystem has both journal and inode journals!
/var/log/messages-20170402:Apr 2 15:08:29 eve kernel: EXT4-fs (sdc1): filesystem has both journal and inode journals!
/var/log/messages-20170402:Apr 2 15:08:30 eve kernel: EXT4-fs (sdc1): filesystem has both journal and inode journals!
/var/log/messages-20170402:Apr 2 15:08:34 eve kernel: EXT4-fs (sdc1): filesystem has both journal and inode journals!
/var/log/messages-20170402:Apr 2 15:08:44 eve kernel: EXT4-fs (sdc1): filesystem has both journal and inode journals!
/var/log/messages-20170402:Apr 2 15:08:47 eve kernel: EXT4-fs (sdc1): filesystem has both journal and inode journals!
/var/log/messages-20170402:Apr 2 15:08:49 eve kernel: EXT4-fs (sdc1): filesystem has both journal and inode journals!
/var/log/messages-20170402:Apr 2 15:08:49 eve kernel: EXT4-fs (sdc1): filesystem has both journal and inode journals!
/var/log/messages-20170402:Apr 2 15:09:46 eve kernel: EXT4-fs (sdc1): filesystem has both journal and inode journals!
/var/log/messages-20170402:Apr 2 15:09:58 eve kernel: EXT4-fs (sdc1): filesystem has both journal and inode journals!
/var/log/messages-20170402:Apr 2 15:11:34 eve kernel: EXT4-fs (sdc1): filesystem has both journal and inode journals!
/var/log/messages-20170402:Apr 2 15:21:39 eve kernel: EXT4-fs (sdc1): filesystem has both journal and inode journals!
/var/log/messages-20170402:Apr 2 15:25:56 eve kernel: EXT4-fs (sdc1): filesystem has both journal and inode journals!
Ein Mounten der Bootpartition war nicht mehr möglich, weil der Superblock defekt war. Im Endergebnis waren zwei Filesysteme der SSD defekt.
Wie konnte das passieren ?
Wenn man Google nach den im Screenshot gezeigten Fehlern befragt, zeichnet sich sehr schnell ab, daß die meisten auf ein Versagen der Stromzufuhr tippen. Das kann man aber wohl ausschliessen, da dabei als erstes die Grafikkarte ausgegangen wäre.
Da ich einige Tage vorher von Fedora 24 auf Fedora 25 umgestiegen bin, und damit auch ein neuer 4.10er Kernel zum Einsatz kam, ist es viel wahrscheinlicher, daß eine Treiber-HW-Kernel-Inkompatibilität vorlag. Das gabs bei Kernel 3.11 und 3.18 schon einmal.
Wie komme ich jetzt darauf ?
Das kommt daher, daß ich an dem besagten 2. April das Stromversagen akzeptiert habe und daher die Stromverbindungen erneuert hatte. Einige Tage später, knallte die gleiche Platte wieder weg, ohne das jemand auch nur in die Nähe der Stecker gekommen wäre. Seit Kernel 4.10.8-200 tritt das Problem nicht mehr auf. Es lag also vermutlich nicht am Strom, sondern an der Kernel-Treiber-HW Kombination.
Filesystem läßt sich nicht mounten
Es waren also zwei Filesysteme defekt. Dummerweise System-Root und die Bootpartition, wobei es die Bootpartition besonders schwer getroffen hatte:
kernel: EXT4-fs (sdc1): filesystem has both journal and inode journals!
Der den Fehler sieht, spart sich am besten gleich den Reperaturversuch und mountet die Platte mit der NOCHECK Option im Readonlymodus und kopiert die noch vorhandenen Files auf ein Backupmedium. Danach dann die Platte frisch formatieren und Daten wieder drauf spielen. Alles andere dürfte Zeitverschwendung sein. (siehe PDF)
Die Systempartition ließ sich im Gegensatz zur Bootplatte recht einfach mit fsck.ext4 reparieren. Daher liegt das Augenmerk des Beitrags auch auf dem Thema: Wie man eine neue Bootpartition aufbaut.
Da ich aus dem Problem und seiner Lösung gleich einen Vortrag für unsere LUG gemacht habe, könnt Ihr Euch jetzt alle nötigen Schritte in einem PDF herunterladen. Ich werde daher auch nur grob auf die einzelnen Lösungswege eingehen. Im PDF sind auch Reparaturanweisungen mit fsck, dumpefs, mke2fs enthalten. Ich empfehle dringend das PDF an einem zugänglichen Ort aufzubewahren, ggf. auch als Offlinekopie 😉
Wie man eine Bootpartition neu aufbaut
Wir nehmen einfach mal an, daß die Bootpartition komplett hinüber ist, was bei dem oben aufgeführten Bug wohl auch der Fall ist. Mein Rettungsversuch mit fsck führte zum totalen Datenverlust, weil einige Inodes doppelt und dreifach belegt waren( vermute ich mal).
Deswegen ist oftmals nur eine neue Partition bzw. ein Reformatieren der Partition der letzte Ausweg.
Da das Formatieren die UUIDs einer Partition ändert, stimmen die Daten auf der Systemplatte nicht mehr.
Um der Sache jetzt folgen zu können, müßt Ihr zwei Dinge wissen:
- Was UUIDs und BLKIDs sind
- Wie die im System benutzt werden um Partition zu referenzieren.
zu 1)
UUIDs werden von LUKS verschlüsselten Festplatten benutzt und sind ziemlich lange, aber eindeutige IDs.
$ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sr0 11:0 1 1024M 0 rom
sdc 8:32 0 111,8G 0 disk
├─sdc2 8:34 0 103,7G 0 part
│ └─luks-ffbd61f2-4c1e-4dc8-b12b-c89e9f69c9fa 253:0 0 103,7G 0 crypt /
├─sdc3 8:35 0 7,6G 0 part
│ └─luks-ca1f019d-39ce-4cf8-b522-f6d3e63ebe2a 253:1 0 7,6G 0 crypt [SWAP]
└─sdc1 8:33 0 525,5M 0 part /boot
sda 8:0 0 1,8T 0 disk
├─sda4 8:4 0 1K 0 part
├─sda2 8:2 0 78,1G 0 part
│ └─luks-6d45b281-c56c-40f0-acf7-c3058d4d6913 253:3 0 78,1G 0 crypt
├─sda5 8:5 0 1,8T 0 part
│ └─luks-7881f602-9462-497d-810a-7d6111ad6085 253:2 0 1,8T 0 crypt /sata_home
├─sda3 8:3 0 7,8G 0 part
│ └─luks-384d6b27-6263-4d53-bfce-e7e5bcd221b9 253:4 0 7,8G 0 crypt
└─sda1
BLKid sind die IDs der Filesystem selbst, also von / , von /home oder /boot . Ein Ext3/4, BTRS usw. Filesystem erzeugt beim Formatieren eine BLKID für sich dieses Filesystem. Jedesmal, wenn die Partition neu formatiert wird, gibt es eine neue Nummer.
$ blkid
/dev/sda1: UUID="aee1b027-ebd7-4ad9-a0ea-0fc881193708" TYPE="ext4" PARTUUID="000c4469-01"
/dev/sda2: UUID="6d45b281-c56c-40f0-acf7-c3058d4d6913" TYPE="crypto_LUKS" PARTUUID="000c4469-02"
/dev/sda3: UUID="384d6b27-6263-4d53-bfce-e7e5bcd221b9" TYPE="crypto_LUKS" PARTUUID="000c4469-03"
/dev/sda5: UUID="7881f602-9462-497d-810a-7d6111ad6085" TYPE="crypto_LUKS" PARTUUID="000c4469-05"
/dev/sdc1: LABEL="Boot" UUID="221608f2-5914-4619-9ef7-6dfddf233fd4" TYPE="ext4" PARTUUID="0000a3dd-01"
/dev/sdc2: UUID="ffbd61f2-4c1e-4dc8-b12b-c89e9f69c9fa" TYPE="crypto_LUKS" PARTUUID="0000a3dd-02"
/dev/sdc3: UUID="ca1f019d-39ce-4cf8-b522-f6d3e63ebe2a" TYPE="crypto_LUKS" PARTUUID="0000a3dd-03"
/dev/mapper/luks-ffbd61f2-4c1e-4dc8-b12b-c89e9f69c9fa: UUID="e62edbbe-a1ae-4242-bca5-1249d6f2df67" TYPE="ext4"
/dev/mapper/luks-ca1f019d-39ce-4cf8-b522-f6d3e63ebe2a: UUID="46da0d80-21fb-45b7-8567-ba047de66cb6" TYPE="swap"
/dev/mapper/luks-7881f602-9462-497d-810a-7d6111ad6085: UUID="196a4455-7ccb-40e4-bc71-7b2929f29225" TYPE="ext4"
/dev/mapper/luks-6d45b281-c56c-40f0-acf7-c3058d4d6913: UUID="0fd1b33c-5a2e-421a-a872-7bfc784ea2cf" TYPE="ext4"
/dev/mapper/luks-384d6b27-6263-4d53-bfce-e7e5bcd221b9: UUID="0bb5a502-f854-4e40-a3bd-08c3a2e6bf22" TYPE="swap"
zu 2)
Jetzt schauen wir uns mal /etc/fstab und den Bootentry im Grub an :
$ cat /etc/fstab
/dev/mapper/luks-ffbd61f2-4c1e-4dc8-b12b-c89e9f69c9fa / ext4 defaults,x-systemd.device-timeout=0 1 1
UUID=221608f2-5914-4619-9ef7-6dfddf233fd4 /boot ext4 defaults 1 2
/dev/mapper/luks-7881f602-9462-497d-810a-7d6111ad6085 /sata_home ext4 defaults,x-systemd.device-timeout=0 1 2
/dev/mapper/luks-ca1f019d-39ce-4cf8-b522-f6d3e63ebe2a swap swap defaults,x-systemd.device-timeout=0 0 0
Wie man in der FSTAB sehen kann, soll /boot über die BLKID eingebunden werden.
Warum macht man das ?
Ganz einfach, weil die BLKID ( BlockID ) eindeutig ist, egal an welchem Port eines Controllers die Platte angebunden ist. Selbst wenn die per USB ins System eingehängt ist, kann man diese Partition referenzieren. Das alt bekannte Problem von früher, wenn sich die Plattenreihenfolge geändert hat, daß dann eine andere Platte das Bootdevice war, entfällt damit.
Wieso ist /boot über BLK referenziert und / mit einer LUKS ID ?
Weil Boot nicht verschlüsselt ist. Das geht zwar auch, aber dann wird es haarig 😉
Da in der FSTAB die BLKID enthalten ist und sich nach erneuten Anlegen des Filesystems eine neue BLKID ergibt, muß man also vor dem ersten Boot die /etc/fstab anpassen, sonst bootet der Rechner nicht mehr.
Der Grub-Booteintrag:
menuentry 'Fedora (4.10.6-200.fc25.x86_64) 25 (Twenty Five)' --class fedora --class gnu-linux --class gnu --class os --unrestricted $menuentry_id_option 'gnulinux-4.10.6-200.fc25.x86_64-advanced-e62edbbe-a1ae-4242-bca5-1249d6f2df67' {
load_video
set gfxpayload=keep
insmod gzio
insmod part_msdos
insmod ext2
set root='hd2,msdos1'
if [ x$feature_platform_search_hint = xy ]; then
search --no-floppy --fs-uuid --set=root --hint-bios=hd2,msdos1 --hint-efi=hd2,msdos1 --hint-baremetal=ahci2,msdos1 221608f2-5914-4619-9ef7-6dfddf233fd4
else
search --no-floppy --fs-uuid --set=root 221608f2-5914-4619-9ef7-6dfddf233fd4
fi
linux /vmlinuz-4.10.6-200.fc25.x86_64 root=UUID=e62edbbe-a1ae-4242-bca5-1249d6f2df67 ro vconsole.font=latarcyrheb-sun16 rd.luks.uuid=luks-ca1f019d-39ce-4cf8-b522-f6d3e63ebe2a rd.luks.uuid=luks-ffbd61f2-4c1e-4dc8-b12b-c89e9f69c9fa rhgb quiet splash audit=0 rd.driver.blacklist=nouveau nouveau.modeset=0
initrd /initramfs-4.10.6-200.fc25.x86_64.img
}Wie man hier unschwer erkennen kann, kommt die BLKID auch im Bootentry vom Bootloader vor, was verständlich ist, weil der sonst nicht weiß welche Platte er booten sollte 😉
Zudem sind hier die zum Systemstart zu entschlüsselnden LUKS Partitionen enthalten. Zudem ist die ROOT Partition mit angegeben, die auch über die BLKID referenziert wird.
Wie stellen wir jetzt aber die Bootpartition wieder her ?
Am einfachsten mit einer LiveCD vom gleichen Distributor . Dann formatieren wir die Bootpartition, so daß diese leer ist und legen uns die BLKID bereit. Folgende Schritte führen dann zum Ziel:
- Systempartition mounten
- DEV und PROC in die Systempartition mounten
- BOOT in die Systemplatte mounten
- CHROOT in die Systemplatte machen
- Bisherige Kernel finden
- Kernel neu installieren
Das sieht dann so aus ( natürlich haben Sie andere Partitionen als ich: SDC2 ist Root, SDC1 ist Boot ). Vorher zum Rootuser werden ( su root ) :
mount /dev/sdc2 /media
mount -t devtempfs devtempfs /media/dev
mount -t procfs procfs /media/proc
mount -t ext4 /dev/sdc1 /media/boot
chroot /media/
Jetzt befinden wir uns im System des normalen Rechners, so daß wir alles so tun können, als wenn er normal gebootet hätte ( ohne Desktop natürlich ) . Wir bekommen die Kernel raus die drauf waren :
rpm -qa | grep kernel-core
und installieren die neu:
dnf reinstall kernel-core-*
Das sind natürlich Anweisungen für Fedora/RedHat Systeme, hier bitte die passenden für Eure Distribution wählen. Natürlich kann man das Raussuchen der Kernels auch weglassen, da ist ja nur eine Info für Euch, damit Ihr seht, ob es stimmt. Nun noch die GRUB Boot Konfiguration neu erzeugen und der Rechner sollte wieder starten:
grub2-install /dev/sdc
grub2-mkconfig -o /boot/grub2/grub.cfg
Das Anpassen von /etc/fstab sollte man natürlich jetzt auch machen, sonst gehts nicht 😉
Wer unerfindliche Probleme mit seinem GRUB Bootentry hat, dem könnte der Beitrag helfen. Ich mußte auch Linux16 durch Linux ersetzen, damit es wieder funktioniert.
Ich kann allen nur nochmal nahe legen, das PDF unten auf einem USB Stick zu sichern, damit Ihr das im Notfall parat habt. Außerdem sind in dem PDF noch viele andere Infos zum Thema aufgeführt und einige intensiver heraus gearbeitet.
PDF zum Download: LUGBS-Filesystemmeltdown