Admins reden sich den Mund fusselig, aber einige Benutzer interessieren sich einfach nicht für Updates der von Ihnen genutzen Software. Was das für Firefox bedeuten kann, beleuchten wir heute.
Firefoxupdate 57 -> 96 – keine gute Idee
Vor ein paar Wochen sollte ich einen defekten Laptop retten.. es war hoffungslos :

Totalschaden
Da haben wir, auch aufgrund des Alters, einfach einen neuen bestellt. Leider hatte der neue nur noch M2 Schnittstellen, aber keine internen SATA Anschlüsse mehr. Also mußte das OS auf eine SSD geclont werden, was an sich eine leichte Übung ist.
Das N15 Acer Extensa EX215-51-52AW
Das mit einem i5 10te Generation, 8GB Ram sowie 256 GB M2.SSD ausgestattete ist ein nettes Gerät, wenn man denn Linux darauf installieren könnte. Natürlich habe ich eine LiveDisk reingesteckt, konnte aber die versprochene SSD nicht finden, egal mit welcher Distro ich es probierte 🙁 Auch im Bios tauchte das Gerät nicht auf. Sachen gibt es.
Stunden später tauchte einem ACER-Forum ein Beitrag auf, daß jemand glaubt vergessen hatte, den Raidmodus des Controllers auf AHCI umzustellen, nur leider gab es da keine Möglichkeit zu im Bios des Geräts.. dachte ich.. eine Weile.. dann stolperte ich immer wieder über diesen Artikel und beiläufig erwähnte jemand eine geheime Tastenkombination, die diesen Wechsel überhaupt erst möglich machte.
Und tatsächlich, die Kombination gab es wirklich: CTRL-s
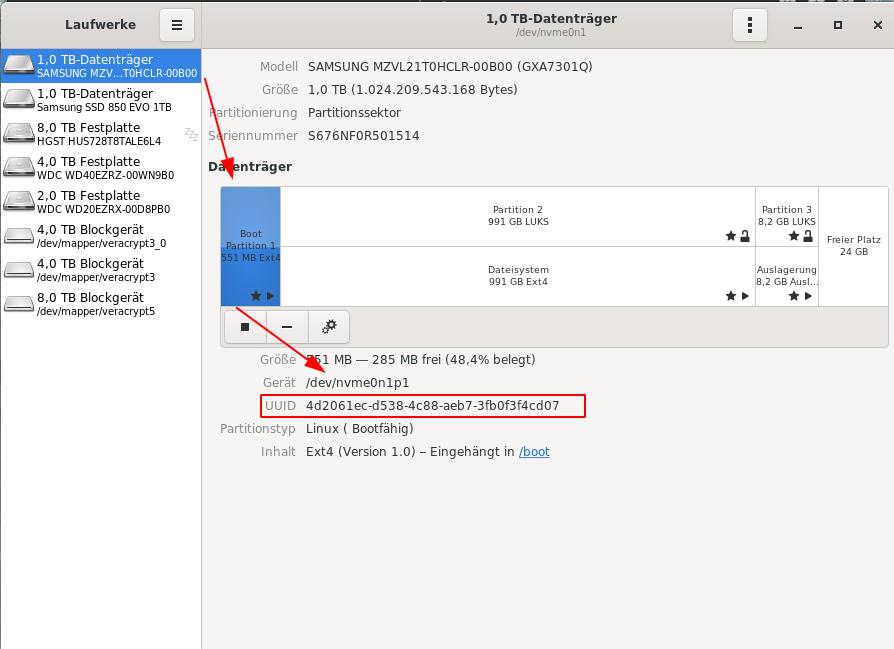
Danach war es ganz leicht, weil sich die SSD endlich meldete. Ein externer SATA-Adapter und ein DD später bootete das Laptop die bisherige Installation. Datenverluste: 0.00 .. so lob ich es mir. Dann der Schock, nicht ganz so unerwartet 😉 Das installierte OS hatte seit 5 Jahren keine Updates gesehen. Eine wandelnde Sicherheitslücke. Installiert war noch Fedora 25 und somit ein Firefox 57, was uns zum eigentlichen Thema des Artikels führt 🙂
5 Jahre keine Updates
Natürlich habe ich in großen Schritten von Fedora 25 auf Fedora 35 aktualisiert. Das Laptop ist echt schnell, also haben 5 Distributionsupgrades nur 2h gedauert ( man muß es ja auch mal runterladen ). Dabei wurde der Firefox von 57 auf 96 aktualisiert, allerdings nur der Firefox, nicht das Profil. Als der Kunde dann seinen neuen Laptop ausprobierte, waren alle Bookmarks, Logins und Passwörter weg. 5 Jahre ohne Updates gehen an keinem Programm spurlos vorbei. Merke: UPDATEN ! UPDATEN ! UPDATEN !
Nun waren die Logins und Passwörter noch in den Profildatenbanken enthalten, es kam aber nichts mehr raus, und kurioserweise ging auch nichts mehr rein.Die übliche Lösung, ein neues Profil anlegen und Key4.db, logins.json und places.db zu kopieren, half nichts, also mußte Mozilla ran. Zur großen Überraschung von den beteiligten Mozilla Devs gab es den Fehler auch bei Ihnen: Beweisvideo von Mozilla
Ein paar Wochen später stand fest: Man kann nicht von 57 auf irgendwas 73+ updaten, ohne daß es zum kompletten Verlust kommt. In Version 72.0.2 wurden die Datenbanken des Profiles intern umstrukturiert und sind damit zu früheren Versionen inkompatibel.
Der Workaround
Der Workaround sieht vor, einfach auf Version 72.0.2 zu downgraden, den dort befindlichen Updatevorgang durch Start von Firefox zu aktivieren und dann die Versionen wieder auf 96, oder jetzt schon 97, hochziehen.
Mit Fedora ist das eher schmerzlos von einem erfahrenen Benutzer zu machen, für Laien aber zu schwierig. Da der Kunde alle seine Passwörter schon von Hand eingegeben hatte, was auch nicht ganz ohne war, gab es für Mozilla und mich nichts mehr zu tun.
Gehen wir das mal theoretisch durch:
su root
dnf downgrade firefox –releasever=32
exit
firefox
su root
dnf update firefox -y
Das wäre es schon. Es könnte sein, daß auf dem Weg noch andere Pakete mit downgegraded werden müssen, was im Einzelfall bei der Zeitspanne von 2,5 Jahren echt spannend sein wird. Natürlich gibt es eine bessere Lösung:
Installiert Euch ein altes System in eine CHROOT-Umgebung 🙂
DNF ist in der Lage eine komplette Basisinstallation in ein beliebiges Verzeichnis vorzunehmen, einfach mit –installroot pfadname angeben. Wenn man da Firefox als Wunschpaket mit angibt, dann zieht das alle Pakete nach, die man dazu braucht, auch einen Desktopmanager usw. Achtet darauf, daß es der gleiche ist, wie der, der gerade läuft, weil Ihr dann natürlich kein System im System mehr startet müßt, was eh nicht geht.
In der Chroot-Umgebung wird dann einfach das alte Profil ins Home kopiert und der Firefox gestartet. Problem gelöst.
Noch bessere Methode
Nichts geht über eine Iteration von Ideen hinaus, oder? 🙂 Vergesst einfach die Chroot, ist viel zu viel Aufwand dafür. Macht Gnome-Boxen auf, startet eine alte, versionsmäßig passende, LIVE-Disk von Eurer Distro, aktualisiert den Firefox auf die 72.0.2 und dann schiebt z.b. per SCP das Profil in die Box und startet den Firefox. Idealerweise legt Ihr vorher noch passend einen Benutzer gleichen Namens an, damit die Pfade stimmen, aber das sollte auch ohne gehen. Danach das geänderte Profil in Eurer Home verschieben. Fertig.
An die Updatemuffel dieser Welt
Eure Strategie ist genauso, wenn nicht noch, riskanter als einfach die Updates mitzumachen!
Sollte nämlich mal ein Update unter Linux nicht laufen, kann man mit einem einfachen Downgrade zurück und schon geht es wieder, außer der Bug wäre in einer Version wie 72.0.2, die die Datenbank an das neue Format anpasst, dann ist das Profil erst einmal unbrauchbar geworden. Deswegen.. Backups! Backups! Backups!