Gestern bei Linux am Dienstag : Recovery ISO Images in Grub einbinden.
Ein Recovery System wird geboren
Gestern Abend konnten wir dank Kanos Hilfe in einem wilden Ritt durch Grub, ein Recovery ISO Image für Fedora in unser Testsystem einbauen, so daß es im GRUB Bootmenü permanent auftaucht, aber nicht auf der Systemplatte hinterlegt ist.
Kommt es zum Bootfail, mal von der totalen Zerstörung der Bootpartition abgesehen, kann über Grub das Recovery ISO Image geladen werden. Ein cleverer Updatemechanismus sorgt dafür, daß es zwar per DNF & RPM installiert werden kann, aber nicht präsent ist, wenn das System läuft. So kann es auch nicht durch unvorsichtige Benutzer oder Software gelöscht werden.
„Wie, nicht auf der Systemplatte hinterlegt?“
Es handelt sich nicht um eine bootbare Partition, das hätte man auch machen können, aber das hat einige Nachteile bei den Updates. Es ist eigentlich nur eine Lagerpartition, auf der das ISO Image draufliegt :
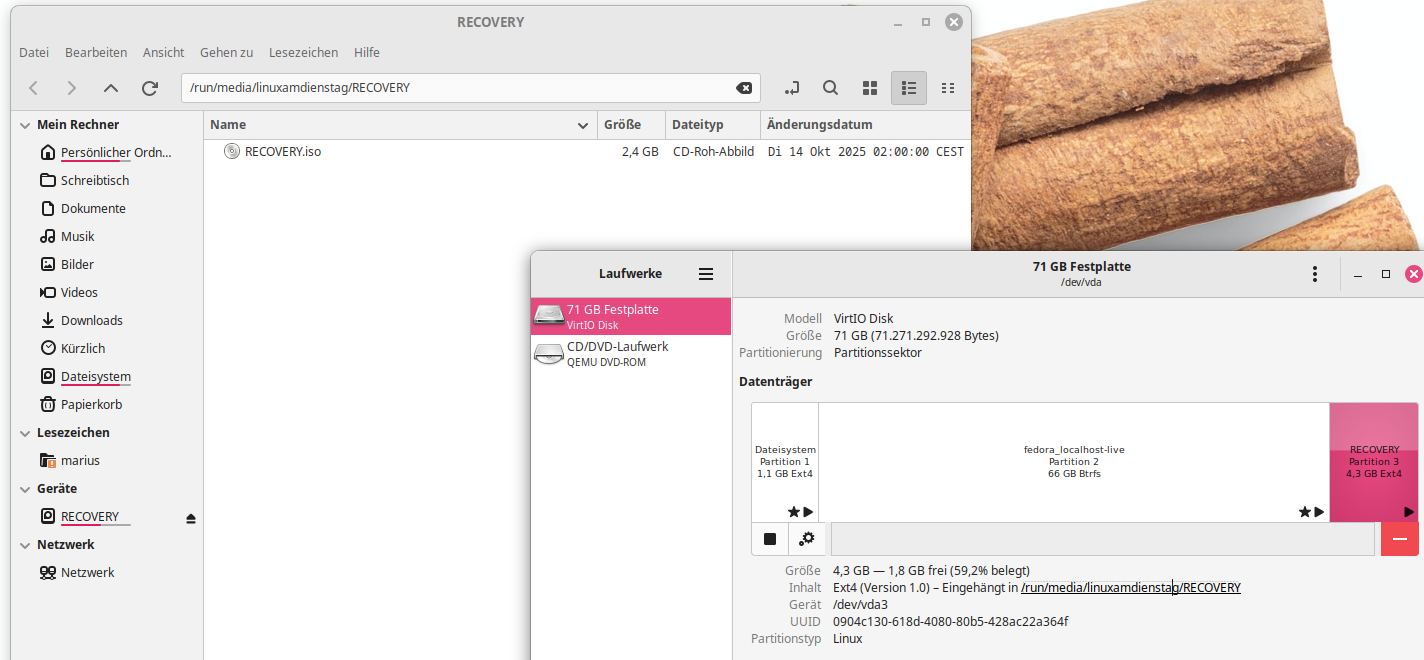
Dazu gehört ein kleiner Eintrag in der /etc/grub.d:
# cat /etc/grub.d/99_RECOVERY
#!/bin/sh
exec tail -n +3 $0
# Copy into /etc/grub2.d and set chmod +x
menuentry „Fedora-RECOVERY“ –class fedora –class gnu-linux –class gnu –class os {
insmod ext2
set isofile=“/RECOVERY.iso„
search -sf $isofile
loopback loop $isofile
linux (loop)/boot/x86_64/loader/linux root=live:CDLABEL=Fedora-WS-Live-42 rd.live.image verbose iso-scan/ filename=$isofile quiet rhgb
initrd (loop)/boot/x86_64/loader/initrd
}
An der Stelle herzlichen Dank an Kano von Kanotix. Er hat die Basis für dieses kleine Script bereitgestellt, der Eintrag selbst ist praktisch mit der LiveBootconfig von der Fedora 42 Livedisk identisch, aber nicht gleich 😉
Dieser GRUB Eintrag durchsucht dank search -sf dateiname alle lesbaren Partitionen nach RECOVERY.iso . Dann wird Grub angewiesen das ISO als Basis zu öffnen und den Kernel daraus nebst initramfs zu benutzen. Das ist ein klein bisschen mehr Aufwand, als wenn die ISO schon auf einem USB Stick ist. Funktioniert aber trotzdem erstaunlich gut.
Hat man das Script eingefügt, muß man es nur noch mit chmod +x /etc/grub.d/99_RECOVERY ausführbar machen und einmal mit grub2-mkconfig -o /boot/grub2/grub.cfg eine neue Grubconfig gebaut werden.
im Grubmenü sieht das dann so aus:
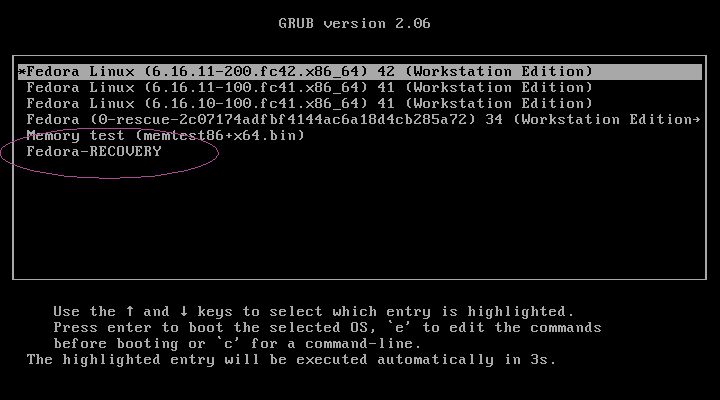
Im Grubbootmenu sieht man den Fedora Recovery Eintrag
Danach bootet einfach das ISO Image normal durch.
Unser Plan für nächste Woche
Da der Boot- und Updatevorgang geklärt ist, Fedorauser können das nämlich bereits im Linux am Dienstag Repo finden, widmen wir uns nächste Woche dann dem Bau des speziellen Liveimages mit all den Tools, die man für ein Recovery so braucht.
ACHTUNG:
Wer das fedora-recovery RPM aus dem Repo testen will, braucht eine min. 3 GB große Partition namens „RECOVERY“. Das richtige Label ist ganz wichtig, weil das RPM darüber die richtige Partition für die Installation findet. Das Filesystem ist dabei in soweit egal, GRUB muß es nur lesen können. Es kommen also min. alle EXT Filesysteme, BTFS und VFAT in Frage.
Selbst wenn Ihr bei der Partition Mist baut, ist das beim Test nicht tragisch, Ihr habt dann einfach nur ein 2,3 GB ISO File unter /usr/share/recovery liegen, das unnötig Platz frisst 😉
Danach bauen wir Scripts um Probleme automatisch zu fixen
In den Wochen danach werden wir versuchen diverse Bootprobleme automatisch zu erkennen und zu fixen.
Am Ende des Projekts könnte ein automatisches Recovery-System stehen, daß normalen Endbenutzern das System wieder herstellt, wenn die es kaputt gemacht haben. Erfahrene Benutzer finden dann dort die Tools, um Ihre etwas heftigeren Probleme selbst zu beheben.
Wo ist jetzt der Vorteil gegenüber einem LIVEImage auf einem USBStick?
Gegenfrage: Wollt Ihr in der Krise erst noch den USB Stick suchen, dann feststellen, daß Ihr gar nicht wisst wo das Bootmenü vom Bios aktiviert wird um dann festzustellen, daß die Tools komplett veraltet sind?
Eher nicht, oder? 🙂 Außerdem wollen wir ja erreichen, daß der Linuxdesktop noch mehr von Normalen Benutzern akzeptiert wird, da muß ein Reparaturtool natürlich auch sehr einfach zu benutzen sein. Damit schlagen wir definitiv ein neues Kapitel im Fedora Desktop auf. Hoffentlich schließen sich da andere Distros mit an.
Übrigens auch für Serverbetreiber wäre das von Vorteil, weil man dann keine „Rescue CDROMS“ mehr in der VM Wechseln müßte, sondern einfach neu booten, ins GRUBMenü gehen und die Rescue starten. Das geht viel einfacher als in der VM erstmal die Bootreihenfolge zu ändern. Denkbar wäre auch eine PXE Bootumgebung, statt einer Partition, dann nimmt der Vorgang weniger Platz weg.