Wenn wir in einem Firmennetz den PCs per DHCP IPs zuweisen, dann kennt nur der DHCP Server die aktuelle Zuordnung aller von Ihm verwalteten Addresseranges und die kann sich dynamisch ändern. Also brauchen wir eine Methode wie wir eine aktuelle Übersicht bekommen.
Windows Netzwerke topologisieren – Linuxstyle
Oh ja.. endlich mal was ohne Corona schreiben, wie ich das vermisst habe 😀
Wir brauchen:
Einen Linux PC
NMAP Scanner
GREP, SED, AWK
nmblookup
nmblookup bekommt man für Fedora im Paket „samba-client“ und nmap natürlich im Paket „nmap„, wer hätte es gedacht 😉
Wir nehmen jetzt mal an, daß wir nur ein Netz haben: 192.168.1.0/24 und, daß Windows RDP offen hat, damit man da auch Remote drauf kann. RDP hat den Port 3389. Das hat den Vorteil, daß wir nur die PCs mit Port 3389 finden müssen:
nmap -n -sS -p 3389 192.168.1.0/24
das sieht dann so aus:
Nmap scan report for 192.168.1.24
Host is up (0.00040s latency).
PORT STATE SERVICE
3389/tcp open ms-wbt-server
MAC Address: A2:54:20:26:3D:7F (Unkown)
Aus der Ausgabe brauchen wir nur die mit offenen RDP Ports, also filtern wir nach „open“, es sei denn, Ihr habt eine Installation bei der das eingedeutscht wurde. Da müßt Ihr selbst ran 😉
nmap -n -sS -p 3389 192.168.1.0/24 | grep -B 3 open
Jetzt habe ich dem ersten grep nach „open“ gesagt, es soll auch die 3 Zeilen vor dem Treffer ausgeben. Dies ist wichtig, weil da die IP drin steht. Als nächstes filter wir auf die IP Zeile:
nmap -n -sS -p 3389 192.168.1.0/24 | grep -B 3 open | grep „scan report“
und werfen alles außer der IP weg:
nmap -n -sS -p 3389 192.168.1.0/24 | grep -B 3 open | grep „scan report“ | sed -e „s/^.*for //g“
Diese Ausgabe müssen wir um den eigentlichen Befehl so erweitern, daß wir die Informationen vom PC bekommen und das geht mit „nmblookup -A <ip>“:
nmap -n -sS -p 3389 192.168.1.0/24 | grep -B 3 open | grep „scan report“ | sed -e „s/^.*for //g“ | awk ‚{print „nmblookup -A „$1;}’|bash
..Das Ergebnis der Mühe wert..
Das Ergebnis sieht dann so aus:
Looking up status of 192.168.1.2
W10-HEIST <00> – B <ACTIVE>
MOVIE <00> – <GROUP> B <ACTIVE>
W10-HEIST <20> – B <ACTIVE>
MAC Address = 52-54-00-48-D1-17
Looking up status of 192.168.1.87
No reply from 192.168.1.9
Looking up status of 192.168.1.188
AUTOCAD02 <00> – B <ACTIVE>
AUTOCAD02 <20> – B <ACTIVE>
INGENIEURE <00> – <GROUP> B <ACTIVE>
MAC Address = 90-1B-0E-53-5E-07
Jetzt habe ich die IP, den Namen, die Arbeitsgruppe und die Macaddresse von jedem Windows PC mit RDP. Jederzeit aktualisierbar. Live 🙂
Das war Teil 1 der Aufgabe, denn für den Fall, für den ich das so gemacht habe, war das das gewünschte Ergebnis. Wir können aber noch mehr machen. Wir haben die IP und die MAC eines PCs.
Was wäre, wenn man damit die Topologie ermitteln könnte?
Vorweg: Es gibt andere Methoden, z.b. snmp Abfragen am Switch und Router, die sind etabliert und funktionieren. Allerdings ist son snmpwalk abhängig davon was die einzelnen Geräte anbieten, da muß man einiges an Zeit reinstecken, wenn man das selbst bauen will.
Zeit ist aber das richtige Stichwort 🙂 Pakete laufen im Netz abhängig von der Strecke zwischen den PCs unterschiedlich lange. Wie bekomme ich das raus? Richtig mit Ping:
# ping -c 20 192.168.1.25
PING 192.168.1.25 (192.168.1.25) 56(84) bytes of data.
64 bytes from 192.168.1.25: icmp_seq=1 ttl=64 time=0.215 ms
64 bytes from 192.168.1.25: icmp_seq=2 ttl=64 time=0.195 ms
64 bytes from 192.168.1.25: icmp_seq=3 ttl=64 time=0.209 ms
64 bytes from 192.168.1.25: icmp_seq=4 ttl=64 time=0.204 ms
64 bytes from 192.168.1.25: icmp_seq=5 ttl=64 time=0.166 ms
64 bytes from 192.168.1.25: icmp_seq=6 ttl=64 time=0.204 ms
64 bytes from 192.168.1.25: icmp_seq=7 ttl=64 time=0.253 ms
64 bytes from 192.168.1.25: icmp_seq=8 ttl=64 time=0.158 ms
64 bytes from 192.168.1.25: icmp_seq=9 ttl=64 time=0.200 ms
64 bytes from 192.168.1.25: icmp_seq=10 ttl=64 time=0.184 ms
64 bytes from 192.168.1.25: icmp_seq=11 ttl=64 time=0.199 ms
64 bytes from 192.168.1.25: icmp_seq=12 ttl=64 time=0.249 ms
64 bytes from 192.168.1.25: icmp_seq=13 ttl=64 time=0.264 ms
64 bytes from 192.168.1.25: icmp_seq=14 ttl=64 time=0.225 ms
64 bytes from 192.168.1.25: icmp_seq=15 ttl=64 time=0.297 ms
64 bytes from 192.168.1.25: icmp_seq=16 ttl=64 time=0.255 ms
64 bytes from 192.168.1.25: icmp_seq=17 ttl=64 time=0.290 ms
64 bytes from 192.168.1.25: icmp_seq=18 ttl=64 time=0.328 ms
64 bytes from 192.168.1.25: icmp_seq=19 ttl=64 time=0.212 ms
64 bytes from 192.168.1.25: icmp_seq=20 ttl=64 time=0.229 ms
— 192.168.1.25 ping statistics —
20 packets transmitted, 20 received, 0% packet loss, time 19360ms
rtt min/avg/max/mdev = 0.158/0.226/0.328/0.047 ms
Wenn wir also statt nmblookup ping einbauen, können wir jeden dieser Pcs messen:
nmap -n -sS -p 3389 192.168.1.0/24 | grep -B 3 open | grep „scan report“ | sed -e „s/^.*for //g“ | awk ‚{print „ping -c 20 „$1;}’|bash | grep -E „(statistics|rtt)“ | sed -e „s/— //g“ -e „s/ ping.*$//g“ -e „s/rtt //“ -e „s/\/max\/mdev = /:/g“ -e „s/\//:/g“ | awk -F „:“ ‚{print $1″=“$3″ „$2″=“$4;}‘ | sed -e „s/= =//“
da kommt sowas bei raus:
192.168.1.21
min=0.624 avg=0.851
Wert ermittelt, jetzt muß er bewertet werden..
Jetzt kann man sich überlegen, inwieweit Ihr dem MIN Wert traut, denn der ist stark vom Netzwerkverkehr abhängig, wo hingegen avg so etwas bedingt ausbügelt. Man sollte die Messung zu verschiedenen Zeiten wiederholen und dann die Ergebnisse zusammenrechnen. Für diese Prinzipdarstellung reichts auch erstmal so 😉
Wir können aus den MIN-Daten folgendes ermitteln: Alle PCs mit der gleichen Antwortzeit sind gleich weit weg, oder der antwortende PC ist ne alte Krücke 😉 Gleich weit weg bedeutet in Wirklichkeit: diese PCs könnten in einem Zimmer stehen, aber die könnten auch in verschiedenen Zimmern stehen, die über gleich lange Kabel angeschlossen sind. Das ist der Knackpunkt.
Üblich ist, daß im Serverraum ein Patchfeld ist, von dem die Kabel in die einzelnen Regionen des Gebäudes abzweigen. Der Vorteil dabei ist der Datendurchsatz und das man PortSense benutzen kann, der Nachteil, daß viel mehr Kabel gezogen werden, als nötig wären.
Datenaustausch in einem Netzwerk
Jetzt überlegen wir mal, welchen Test wir noch machen können… hmm.. IP.. Name… MACAdressse… MACAdresse… hey, wir haben eine MACAdresse vom PC direkt.. vergleichen wir die doch mal mit dem was im Arptable steht 😀
Erstmal erklären: Der Datenaustausch findet in einem Netz nicht zwischen IPs statt, sondern zwischen MAC Adressen. Das sind die Adressen der Netzwerkkarten die da zum Einsatz kommen. Haben wir eine direkte Verbindung zu dem Austauschpartner, hat die IP im Arpcache die gleiche Macadresse wie die per nmblookup mitgeteilt wurde. Im ARP Cache, erreichbar über den Befehl apr, bekommen wir die für die Kommunikation zur IP genutzte Mac auf dieser Seite der Verbindung:
Looking up status of 192.168.1.51
…
MAC Address = B1-6E-FF-D3-42-B4
# arp |grep 1.51
192.168.1.51 ether b1:6e:ff:d3:42:b4 C eth0
Ist da aber ein anderes Gerät dazwischen ( z.B. Router ), dann hat das Arpcache bei uns eine andere MAC als das Gerät uns per nmblookup mitgeteilt hat. Hinweis: Switche geben Ihre eigenen MAcs nicht preis, die sind transparent was das betrifft. Ein Router könnte jetzt also ein Netzumsetzer, eine Bridge, Tunnel oder ähnliches sein:
Looking up status of 192.168.1.51
…
MAC Address = B1-6E-FF-D3-42-B4
# arp |grep 1.51
192.168.1.51 ether A0:43:3d:3A:13:45 C eth0
Wenn man jetzt also mehrere IPs mit der gleichen MAC hat, weiß man, daß die zusammen auf entweder einer Hardware laufen, dann wären die Pingzeiten alle gleich, oder die laufen alle durch einen Router/Tunnel und haben unterschiedliche Laufzeiten, dann stehen die hinter dem Router an verschiedenen Stellen.
Andere Ergebiskombinationen
Jetzt gibts noch die Kombi, daß die Laufzeit für einige IP gleich ist, die Mac auch, aber die Mac noch bei anderen IPs auftaucht, die andere Laufzeiten haben, dann sind die IPs mit gleicher Laufzeit auch auf einer anderen Hardware hinter so einem Router platziert und der Rest steht irgendwo anders.
Wenn man nur von einem Standort aus scannt, bekommt man möglicherweise einen falschen Eindruck, weil wir die „Welt“ nur zweidimensional sehen. Wenn unserer erstes Zwischengerät seine MAC anzeigt, könnten da noch einige andere hinter liegen, die wir nicht mehr sehen können. Deswegen ist eine automatische Topologie zumindest mit dieser simplen Methode hier, bei komplexen Setups nicht ausreichend genau.
Das war natürlich jetzt nur eine theoretische Überlegung, ich hatte ja gesagt, daß es da etablierte Methoden gibt. Wann könnte das also noch mal wichtig sein? z.B. wenn man mit LAHA Audio zeitgleich ans Ziel streamen will: Multi-Netzwerk-Lautsprecher mit Linux
Hier wäre, wenn wir es schon eingebaut hätten, die Laufzeit eine wichtige Komponente, damit die Streams alle zeitgleich zu hören sind. Vielleicht baue ich das ja mal ein. Ich habe gerade erst AndroidStudio wieder zum Leben erwecken können 😀
Anmerkungen:
Alle MACs sind frei erfunden. Je nach Aufgabenstellung kann man auch andere Ports als Scankriterium für Nmap oder gleich einen PING-Scan benutzen. NMAP gibt u.U. einen aufgelösten Domainnamen zurück:
Starting Nmap 7.80 ( https://nmap.org ) at 2020-08-19 13:14 CEST
Nmap scan report for android-501a417bc9ee518.fritz.box (192.168.0.39)
Host is up (0.090s latency).
PORT STATE SERVICE
445/tcp closed microsoft-ds
MAC Address: 6C:F1:76:2D:3B:AA (Samsung Electronics)
da müßt Ihr die SED Anweisungen entsprechend ändern oder nmap die „-n“ Option verpassen, sonst passieren skurille Dinge :DD
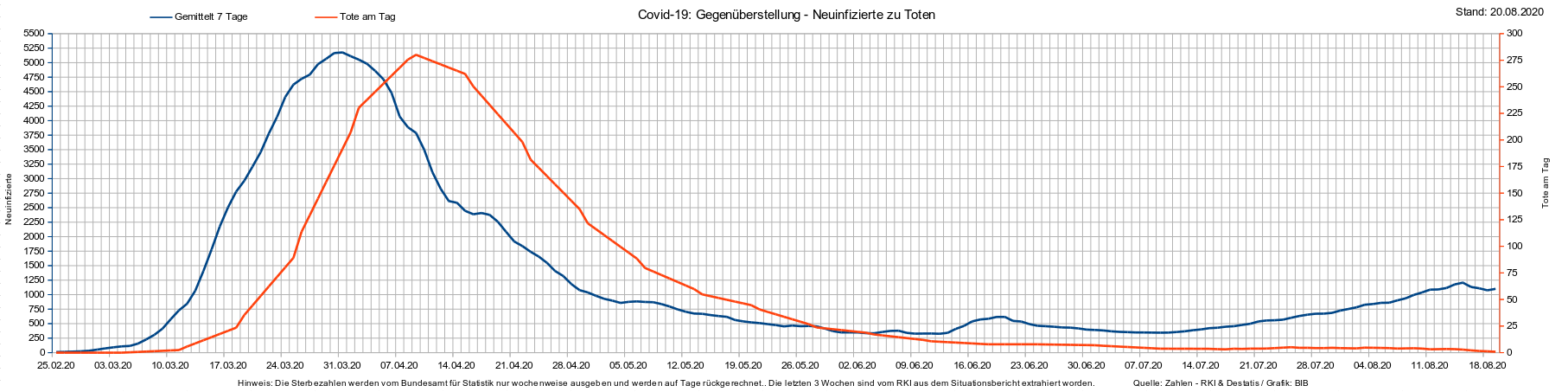 Damit es auch alle verstehen: Bei der ersten Welle, folgte auf den Anstieg der Infiziertenzahlen zeitverzögert rund 13 Tage später ein Anstieg der Verstorbenenzahlen. Jetzt, im August und schon im Juni, fehlt dieser Anstieg.
Damit es auch alle verstehen: Bei der ersten Welle, folgte auf den Anstieg der Infiziertenzahlen zeitverzögert rund 13 Tage später ein Anstieg der Verstorbenenzahlen. Jetzt, im August und schon im Juni, fehlt dieser Anstieg.