„Boar, wie geil..“ war das Echo, als meine neueste Erweiterung für Carola im Familienkreis vorgestellt habe, also sollt auch Ihr daran teilhaben 🙂
Twinkle, Twinkle little PVA …
Bislang kam bei Carola, unserem Lieblings-Personal-Voice-Assistant, Jitsi beim Telefonieren zum Einsatz, weil es das brauchbarste SIP Programm war. Das hat sich radikal geändert, als Twinkle auf der Bildfläche erschien.
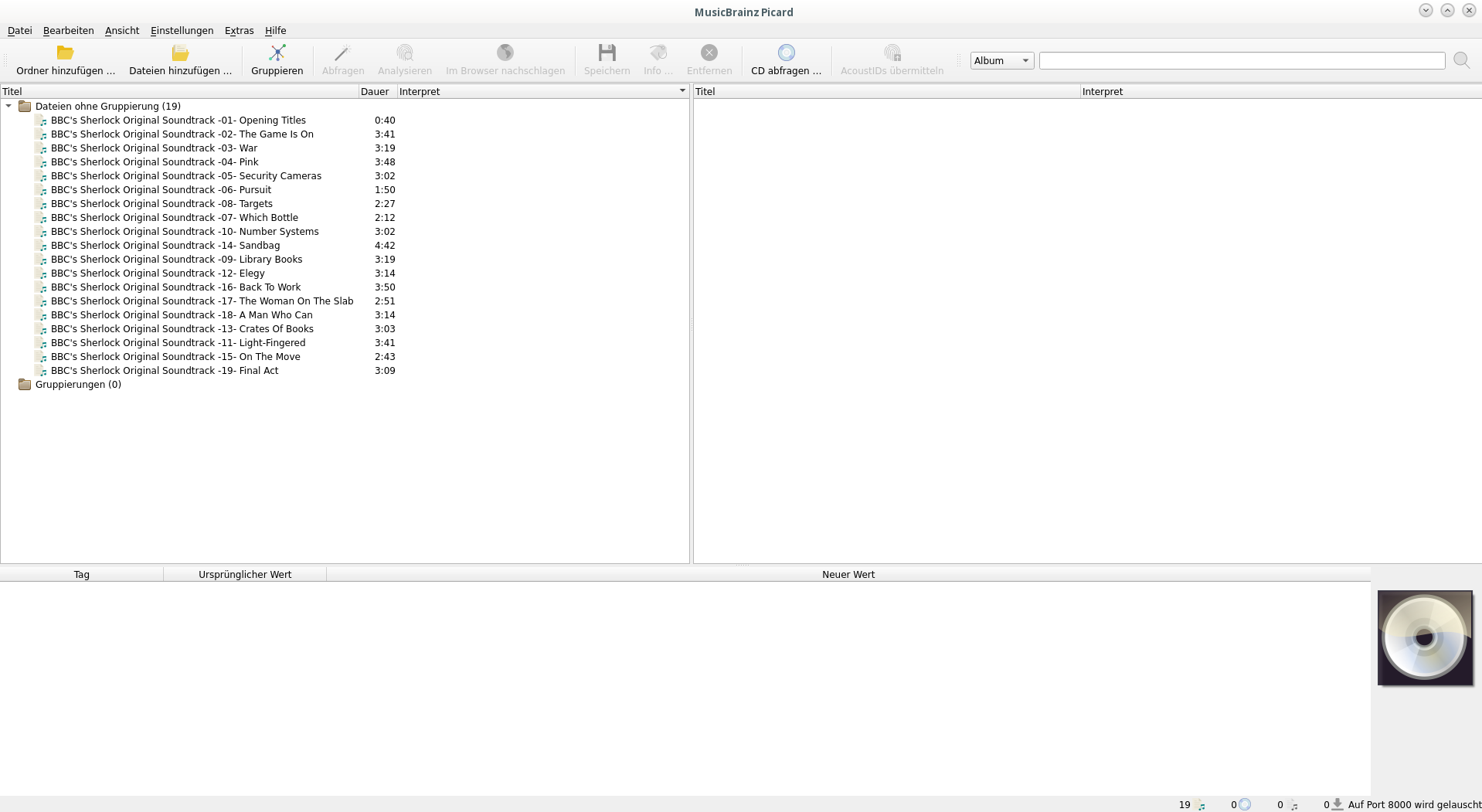
Die Oberfläche von Twinkle, daß mit zwei Leitungen auch mal eine Dreierkonferenz makeln kann, ist eher ernüchtern:
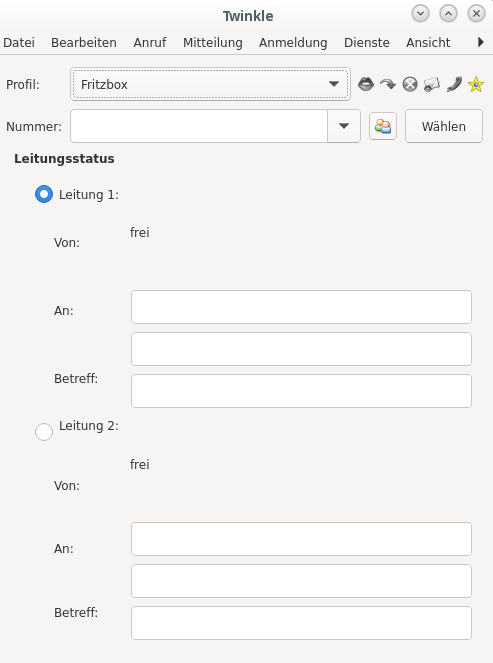
Main-UI von Twinkle.
Da Twinkle im Livebetrieb diese UI nicht offen haben muß, kann man das verschmerzen. Die UI von Jitsi ist klein, schön und kompakt, so wie man das von klassischen InstantMessangern erwartet. Bei Twinkle geht es aber hauptsächlich um SIP, über das man auch Nachrichten schicken kann, und cooles Aussehen nicht so wichtig 😉
Der schwierigste Teil von Twinkle ist seine Konfiguration, aber nur, wenn man den SIP-Providernamen falsch angibt. Merkt Euch mal: IMMER den Domainnamen angeben, also sipgate.de, fritz.box usw. NIE die IP!
Ok, jetzt haben wir ein funktionierendes SIP-Programm, was das mit Carola zu tun hat, dürfte Euch natürlich klar sein, man kann damit jemanden Anrufen. Das war natürlich der erste Test, also sagen wir Carola, wir wollen mit X sprechen, Carola sucht die Nummer raus, teilt das Twinkle mit und das ruft dann die Nummer an. Soweit hatten wir das schon mit Jitsi, wenn Ihr Euch erinnern mögt, steht auch so in der Default Config vom PVA drin.
Eigentlich nicht weiter spannend, dann können wir jetzt aufhören… Sekunde mal, das Telefon klingelt.
„Carola am Apparat“
„Wie war Ihr Name?“
„Müßten Sie das nicht wissen, Sie haben doch mich angerufen“
„ich will mit meiner Tochter sprechen“
„geht nicht, ist nicht da.“
„können sie ihr sagen, das ich angerufen habe“
„nein, kann ich sonstwie helfen?“
Wäre die Google Stimme noch etwas besser, wäre das Gespräch oben geeignet gewesen, einen Menschen zu täuschen. So aber ist es nur unsere neueste Errungenschaft: Carola nimmt aktiv das Telefonat an und spricht mit den Anrufenden \o/
Die für das Gespräch nötige Config sieht so aus:
reaction:“wie war ihr name“,““,“Mein Name ist %KEYWORD“
reaction:“wer ist da“,““,“Hier ist %KEYWORD. Was möchten Sie von mir?“
reaction:“wer ist da“,““,“Sollten Sie das nicht wissen, sie haben mich angerufen!“
reaction:“ich will mit [Haushaltsmitglied1] sprechen“,““,“der ist unterwegs mit seiner Tabletschlampe Anja“
reaction:“ich will mit [Haushaltsmitglied2] sprechen“,““,“tut mir leid, die ist nicht zu sprechen.“
reaction:“ich will mit|sprechen“,““,“Ist nicht da“
reaction:“ich will mit|sprechen“,““,“Die Person ist mir unbekannt“
reaction:“ich will mit|sprechen“,““,“Pech gehabt, nicht da“
reaction:“ich will mit|reden“,““,“kenn ich nicht“
reaction:“ich will mit|reden“,““,“Pech gehabt, nicht da“
reaction:“können sie eine nachricht“,““,“nein, die Funktion ist noch nicht eingebaut“
reaction:“können sie eine nachricht“,““,“das tonband ist defekt“
reaction:“können sie eine nachricht“,““,“rufen Sie einfach später nochmal an.“
reaction:“können|sie|sagen|das“,““,“rufen Sie einfach später nochmal an.“
reaction:“können|sie|sagen|das“,““,“nein, kann ich sonstwie helfen?“
reaction:“können|sie|sagen|das“,““,“nein, der mp3-rekorder ist defekt“
Das ist natürlich nur ein Teil. Vorher müssen wir noch ein paar coole Techniken benutzen, damit sich Carola und wer auch immer da anruft, unterhalten können.
Der Pulseaudio Part
War klar, oder? Ohne Pulseaudio geht so etwas nicht, weil man PA erzählen extern kann, wo welches Programm seinen Sound ausgeben soll. Jetzt muß ich etwas ausholen, denn ich habe zwei Audiogeräte im PC:
- Die Mainboard Lautsprecher
- Einen HDMI Monitor mit Köpfhörerausgang
Wie Ihr vielleicht wisst, gibt es zu jedem Ausgabegerät unter Pulseaudio auch die Möglichkeit einen Monitor davon als Eingabegerät zu verwenden. Ihr ahnt vermutlich jetzt, wo die Reise hingeht. Wir verdrahten die Ausgabe von Twinkle zur Aufnahme von Carola und umgekehrt.
Da Carola über gsay/say Ihre Sätze an den Lautsprecher schickt, ist es tatsächlich so, daß Twinkles Aufnahme auf den Monitor vom Mainboard geht und Carola kurzfristig das HDMI Gerät belauscht, auf dem Twinkle die Sachen ausgeben wird.
Der Scriptteil
Damit das klappt, braucht es zwei Bashscripte: pulse.out + pulse.in
pulse.out stellt die Ausgaben um, pulse.in die Aufnahmen. Die Scripte könnt Ihr hier finden:
https://github.com/Cyborgscode/Personal-Voice-Assistent/tree/main/plugins/twinkle
Zur Technik:
Schritt 1 – Die Sinkid finden, auf der ein Prozess seine Ausgaben macht
echo $( LANG=C pactl list sink-inputs | grep -e „Sink\ Input“ -e „node.name“)
Geht den Befehl wenn Musik läuft ein, da kommt das raus:
Sink Input #543 node.name = „qmmp“
LANG=C ist nötig, damit es eine definierte Sprache gibt, die parsebare Ergebnisse liefert. Sonst müßte man das Script auf alle Sprachen erweitern. Jetzt haben wir die SinkID von QMMP und müssen wir noch wissen wohin die Reise gehen soll: pactl list sinks | grep „Name:“
kommt u.a. so ein Treffer: „alsa_output.pci-0000_0a_00.4.analog-stereo“ Das ist in meinem Fall, die normale Lautsprecherausgabe vom Mainboard. Jetzt noch in einer Anweisung zusammen bringen:
pactl move-sink-input 543 alsa_output.pci-0000_0a_00.4.analog-stereo
Damit ist QMMP auf die Lautsprecher gelegt. Jetzt als Befehl fürs Script: pulse.out qmmp default
Wenn Ihr die Scripte zu hause benutzen wollt, dann müßt Ihr die Aus/Eingabe-Gerätenamen anpassen.
Damit kann man jetzt schon neue Funktionen für Carola bauen:
command:“schalte auf kopfhörer“,“EXEC:pulse.outx:x{config:audioplayer:pname}x:xhdmi“
command:“schalte auf lautsprecher“,“EXEC:pulse.outx:x{config:audioplayer:pname}x:xdefault“
command:“schalte um auf kopfhörer“,“EXEC:pulse.outx:x{config:audioplayer:pname}x:xhdmi“
command:“schalte um auf lautsprecher“,“EXEC:pulse.outx:x{config:audioplayer:pname}x:xdefault“replacements:“h d m i“,“hdmi“
replacements:“u s b“,“usb“command:“schalte .* um auf kopfhörer“,“EXEC:pulse.outx:x%0x:xhdmi“
command:“schalte .* um auf lautsprecher“,“EXEC:pulse.outx:x%0x:xdefault“
command:“schalte .* auf .* um“,“EXEC:pulse.outx:x%0x:x%1″
Die ersten vier Zeilen schalten den Default-Audioplayer um. Das ist eine nette kurzversion des Befehls. Mit {config:audioplayer:pname} bekommen wir den konfigurierten Prozessnamen von, in dem Fall, qmmp. Damit ist klar, wen das Script umschalten soll.
Die letzten drei Befehle wiederum nehmen einen beliebigen Prozessnamen an und schalten diesen Prozess auf wiederum beliebige Geräte um. (Spart es Euch, das ist doppelt exploitsicher, egal wie oft Ihr da ein ; einfügen wollt, es wäre nur ein Argument, keine Bashanweisung UND versucht mal Semikolon über eine Spracheingabe als ; einbauen zu lassen 😀 ) Da kann man also auch firefox oder twinkle angeben.
Das alleine reicht aber noch nicht für den Trick, ist aber eine sehr wichtige Grundlage!
Die Twinkleanbindung
Jetzt stellt Euch mal die Frage: „Woher weiß der PVA, daß jemand anruft?“ Antwort: „Weiß er nicht.“
Folgerichtig muß Twinkle die Arbeit leisten und Carola andocken 🙂 Dazu brauchen wir das hier:
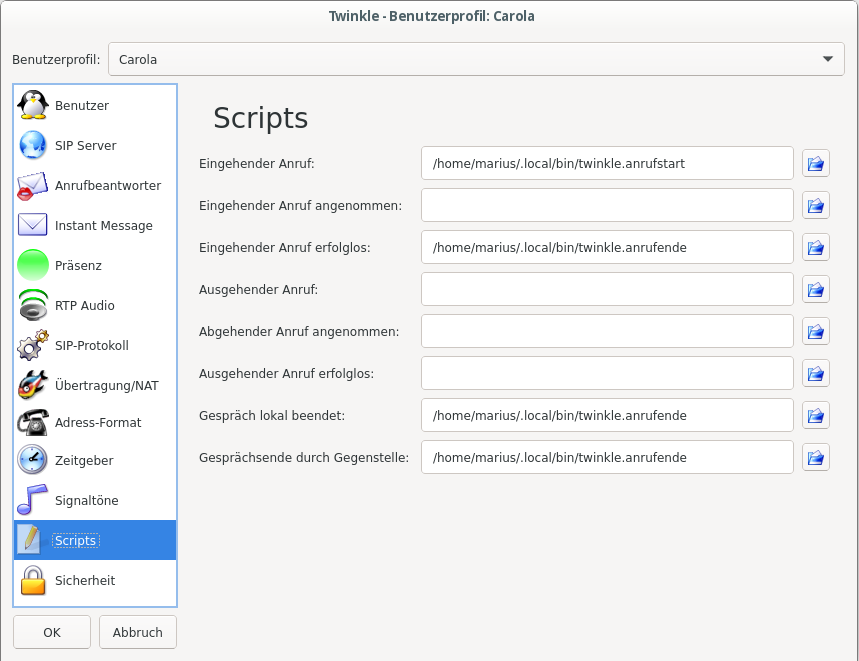 und dazu brauchen wir die zwei Script ( auch auf Github ) :
und dazu brauchen wir die zwei Script ( auch auf Github ) :
#!/bin/bash
echo „action=autoanswer“
echo „end“
sleep 2s
pulse.in „PipeWire ALSA [python3.10]“ hdmimonitor
pulse.in „PipeWire ALSA [twinkle]“ defaultmonitor
pulse.out „PipeWire ALSA [twinkle]“ hdmi
gsay „Hi, Carola am Apparat“
Die beiden ersten Anweisungen sind an Twinkle selbst, sofort abzuheben und nicht mehr auf das Script zu warten. An der Stelle kann man auch noch eine spezielle Behandlung für bestimmte Anrufer einbauen, in dem man auf die CallerID checkt, aber das brauchen wir nicht.
Wir warten jetzt 2 Sekunden, damit alle Sinks aktiv sind und unsere Pulse.in und Pulse.out Scripte Ihre Magie ausführen können.
Wenn das gespräch beendet wird, was Carola nicht beeinflussen kann, kommt das Gegenscript zum Einsatz:
#!/bin/bash
pulse.in „PipeWire ALSA [python3.10]“ usb
pulse.in „PipeWire ALSA [twinkle]“ usb
pulse.out „PipeWire ALSA [twinkle]“ default
echo „action=end“
Alles wird wieder auf normal umgestellt. Wenn wir da sind, können wir , in meinem Fall, über die Kopfhörer den Anrufer hören und über den Lautsprecher was Carola sagt. Das hat den Vorteil, daß wenn der Anrufer z.b. ein Programm mit Tonausgabe startet, er das auch hören kann, weil für alle anderen Programme außer Twinkle, hat sich nichts an der eingestellten Konfig geändert.
Jetzt seid Ihr dran
Ok, Freunde, an der Stelle überlasse ich Euch jetzt das Feld. Ich will ausgeklügelte Telefonreaktionsketten sehen, in denen ein Anrufer solange wie möglich am Telefon gehalten wird 🙂 Die besten kommen ins Github!