Die aktuelle Version von Dovecot für Fedora, Version 2.3.15, hebt über die internen Defaulteinstellungen das MinimalProtokoll für TLS von TLS 1.0 auf TLS 1.2 an, ganz zum Nachteil alter Mailprogramme.
Dovecot 2.3.15: Update kickt alte Mailclienten raus
Montag Morgen, Internet: Gegen 6 Uhr morgens weisen die Fedoraserver eine neue Dovecotversion aus. Wenige Sekunden später fangen die ersten Server im Cluster an, das Update einzuspielen. Gegen 8 Uhr kommen die ersten Beschwerden beim Support rein, daß einige Benutzer keine Emails mehr abholen könnten.
Eine Analyse später steht nur fest, daß die Clienten beim Abholen eine „nicht unterstützte TLS Version sprechen“, komischerweise aber noch Emails senden können. Die Zugriffe der Mailprogramme findet dabei über die seit 1994 in Betrieb befindlichen SSL-Ports 993 und 995 statt, was die Vermutung nahe legt, daß die Mailprogramme dabei auch das damals übliche SSLv3 sprechen oder zumindest nicht TLS 1.2+.
In den Adminkreisen kommt der Verdacht auf, ein Windowsupdate hätte das Problem verursacht, was sich aber als falsch herausstellt, da nach und nach auch Android und Macuser Probleme melden.
24h später steht die Ursache fest: Das Dovecot Update 2.3.15 bringt ein Securityupdate mit, in dessen Zuge die minimale Protokollversion für TLS Verbindungen von TLS 1.0 auf TLS 1.2 gesetzt wird. Eine Umstellung der Mailprogramme aus das moderne STARTTLS stellt in den Mailprogramm dann auch die verwendete Krypto von „völlig veraltet“ auf „modern“ um, so daß die Probleme mit einen Klick behoben werden können.
Im Changelog liest sich das übrigens so:
– CVE-2021-29157: Dovecot does not correctly escape kid and azp fields in JWT tokens. This may be used to supply attacker controlled keys to validate tokens, if attacker has local access.
– CVE-2021-33515: On-path attacker could have injected plaintext commands before STARTTLS negotiation that would be executed after STARTTLS finished with the client.
– Add TSLv1.3 support to min_protocols.
Da die Sicherheitslücken nicht umgangen werden können, bleiben die alten Versionen draußen. Dies hat uch den Vorteil, daß jetzt TLS 1.2 das Mindestmaß auch bei Privatanwendern ist.
Zwei Einzelfälle möchte ich Euch allerdings nicht vorenthalten:
a) Ein Benutzer nutzte auch beim Senden noch TLS 1.0, was den Verdacht nahelegte, daß hier eine alte Version in Spiel war. Es kam raus, daß noch Thunderbird V17 von 2013 benutzt wurde und nie Updates eingespielt wurden 🙂 Ein Update wirkte Wunder 😉
b) Ein anderer Benutzer nutzte auch noch TLS 1.0, aber hier war Hopfen und Malz verloren, da es sich um einen MAC von 2006 oder 2007 handelte. Dem ist in sofern nicht mehr zu helfen, da es hier keine Updates mehr gibt, die diese HW noch mitmachen würde.
Merke: Alte Hardware ist nur charmant, wenn Sie auch noch sicher ist.

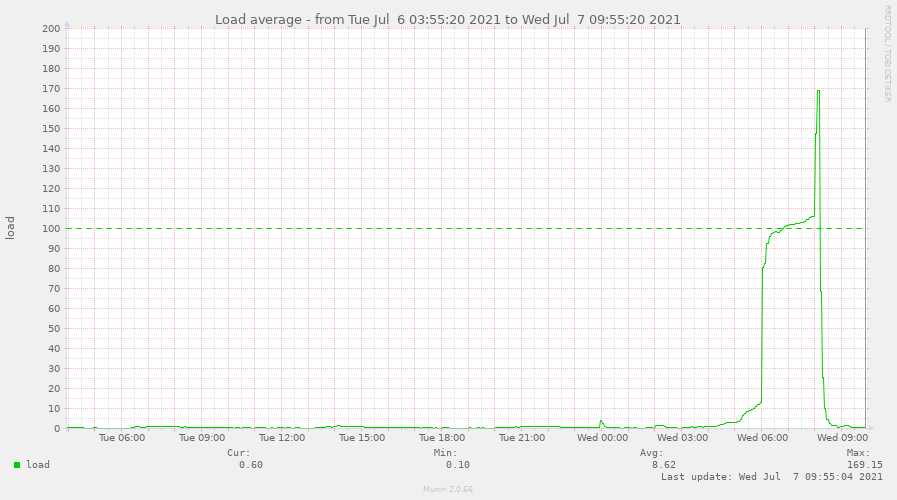 Der Graph wird nur alle 5 Minuten erzeugt, daher die leicht abgeflachte Spitze
Der Graph wird nur alle 5 Minuten erzeugt, daher die leicht abgeflachte Spitze