Erst war es nur eine Idee, dann wurde es doch Realität: MP3 Metadaten 😉
neue Features für PVA Carola
Als ich in 2021 angefangen habe mit Carola einfachste Anweisungen umzusetzen, kamen schnell möglich Anwendungsfelder ins Spiel z.b. ein naheliegender Gedanke: auf Zuruf Musik abspielen können. Also schaute ich mir meinen Lieblingsplayer QMMP genauer an und der konnte alles per Kommandozeile mitgeteilt bekommen, was für ein Programm, daß eigentlich nur Bashbefehle absetzt naheliegend ist.
Natürlich reicht das nicht, weil man Musik ja auch suchen muß. Wer wie ich jetzt Spotify in Klein zu hause hat, der macht aus der kleinen Aufgabe, mal eben das ~/Musik Verzeichnis zu durchsuchen eine abendfüllende Angelegenheit, weil trotz M2.SSD der Suchvorgang recht lange braucht. Also cacht man trotzdem alles, was man so cachen kann, in diesem Fall alle Pfade und Dateinamen, damit man nur noch eine Datei laden und durchsuchen muß, was nicht mehr Minuten, sondern nur (Bruchteile von) Sekunden dauert.
Jetzt kann man mit einer vernünftigen Benennungsstrategie, recht gute Treffer für Begriffe wie „Queen“, „Elton John“ oder „Alles nur geklaut“ erzielen, aber grundlegende Suchen nach dem Genre fallen weg, weil man das üblicherweise nicht in den Dateinamen schreibt. Da andere Sachen wichtiger waren, blieb es also erst einmal bei dieser simplen Methode.
com.mpatric.mp3agic hat das geändert
Da es noch keine Methode gab, die Musiksammlung durch Metadaten nach Genres abspielen zu lassen, ohne dabei auf andere Audioplayer zu setzen, die nicht das Look&Feel von QMMP hatten, gab es auch keinen Grund die Musiksammlung dahin gehend zu indizieren und die Tags in die MP3-Dateien zu überführen. Wir hatten also ein Henne-Ei-Problem 😉
Github ist ein Hort von Software für fast alles und die JAVA Bibliothek com.mpatric.mp3agic konnte sehr einfach MP3Files auf alles mögliche analysieren. Leider dauerte ein Scan meiner fünfstelligen Sammlung bequeme 10 Minuten. Der Wert ist natürlich für eine Direktsuche viel zu schlecht. Michael, der Autor von mp3agic, konnte die Zeit durch Tipps auf unter 5 Minuten drücken aber auch das war mir noch zu lange.
Java kann eigentlich sehr einfach Subprozesse erzeugen und koordinieren, so daß ein gemeinsamer Datensatz erzeugt werden kann. Hmm.. also was macht man, wenn ein Sequenzielles Verarbeiten von Daten zu langsam ist und genug Prozessoren zur Verfügung stehen? Genau man parallelisiert den Vorgang 😀
Load 12000 – Tendenz steigend!
Ich hatte Carola vor einigen Wochen beigebracht mir den Status des PCs in menschlicher Form mitzuteilen, also nicht einfach stumpf die Load aufsagen, sondern abhängig von der Load entsprechend immer dramatischer klingende Sätze von sich zu geben, bis hin zur Überlastung mit Rotem Alarm und Warnsirenen 🙂 Leider war Carola im ersten, zu erfolgreichem, Versuch selbst die Ursache, so daß es mir leider keinen Kommentar zur Load von 12.000!!! geben konnte 😀

Die CPU brennt? 😀
Eine Load von 12.000 habe ich selbst in 20 Jahren Linux noch nirgendwo gesehen, entsprechend ungläubig habe ich mir die Werte in Top angesehen 😉 Aber wenn man mehr als 10.000 Prozesse gleichzeitig auf 12 unschuldige CPU Kerne loslässt, dann geht die Load relativ schnell nach oben, wenn die IO-Last steigt. Wenn man Anfangs noch 300 Prozesse gleichzeitig von der SSD hat versorgt lassen können, wird das für jeden Prozess der dazu kommt und für den noch kein früherer beendet wurde, immer langsamer, selbst mit „Bis zu 1.000.000 IOPS“ lesend (Samsung Werbung) , weil gar nicht genug Daten am Stück gelesen werden, so ein MP3-File ist ja schliesslich endlich, kann die SSD das nie ausspielen. Dazu kommt noch, daß ein Teil der Daten auf langsameren SATA SSDs oder SATA HDDs gespeichert waren, was die IO-Last deutlich steigert und die Performance drastisch in den Keller zieht.
Anders als bei einem SWAP-of-Death Zustand, ist eine Load von 12.000 kein Problem. Das System läuft bequem weiter, weil die CPU zwar durch IO-Wait gebremst werden, aber alle anderen Prozesse deswegen trotzdem ausgeführt werden können. Das Starten von neuen Anwendungen wird zum Problem, aber z.b. lief die Musik auch störungsfrei durch. Abbrechen kann man die Prozesse so auch leicht.
Wie aus 10+ Minuten 1,5s wurden
Vorteilhaft ist es, die nötigen Blöcke der Dateien bereits im Filecache des OS zu haben, aber um das zu erreichen muß man, welch Wunder, genau diese Blöcke schon einmal gelesen haben. Wenn man das gemacht hat, dann braucht man den zweiten Lauf nicht mehr, weil man das Ergebnis bereits hat. Nur der Statistikfreaks wegen, hier der Benchmark für einen Ryzen 5600X mit DDR4 3200MHz RAM: (bestwert) 1,5s auf 14.000+ Files.
Um den ersten Lauf durchzuführen, braucht man mit der Methode wahnsinnig viel Zeit, fast soviel wie sequenziell, weil durch die vielen Prozesse keiner der Prozesse richtig fertig wird, weil laufend Kontextswitche in der CPU und damit im IO-Controller stattfinden müssen, was höllisch inperformant ist. In der Praxis ist es daher besser ein niedrigeres Limit für die maximale Anzahl an Prozessen zu setzen, so daß die Platten hinterher kommen und die Kerne gut ausgelastet sind. Ich habe da mal 200 als Limit angesetzt.
Ohne Limit dauerte der Vorgang (ungecacht) :
$ time java PVA ‚:“carola erzeuge metadata“‚
erzeuge metadata
found MAKEMETACACHE:
real 15m39,380s
user 0m24,000s
sys 0m9,338s
Mit Limit 200 UND Debugausgabe in Terminal wo er ist…
argument:Das Metacache wurde aktualisiert.
real 0m44,807s
user 0m3,886s
sys 0m2,852s
Mit Limit 200, MIT Filecache UND OHNE Debugausgabe in Terminal wo er ist…
$ time env java PVA ‚:“carola erzeuge metadata“‚
erzeuge metadata
found MAKEMETACACHE:
real 0m3,385s
user 0m3,351s
sys 0m1,800s
Ich denke, das ist ein guter Kompromiss zwischen den Extremen 😉 Ist das Filecache richtig gefüllt, ist es auch egal wieviele Prozesse parallel starten: ob es 200, 2.000 oder 20.000 sind spielt dann keine Rolle mehr. Im ungecachten Zustand ist aber ein wichtiger Faktor, weil die Anzahl der Prozesse die IO-Last reguliert.
Merke: Das Filecache im RAM ist extrem wichtig!
Wie kommt man die Metadaten ran?
Dazu benutzt man am besten PICARD. Ja, ich dachte auch erst an TNG 😉
Mit Picard habt Ihr ein gutes Tool, das schnell, und meisten recht einfach, die Metadaten aus der MusicBrainz Datenbank auslesen kann. Es schreibt dann die Metadaten in die Files.
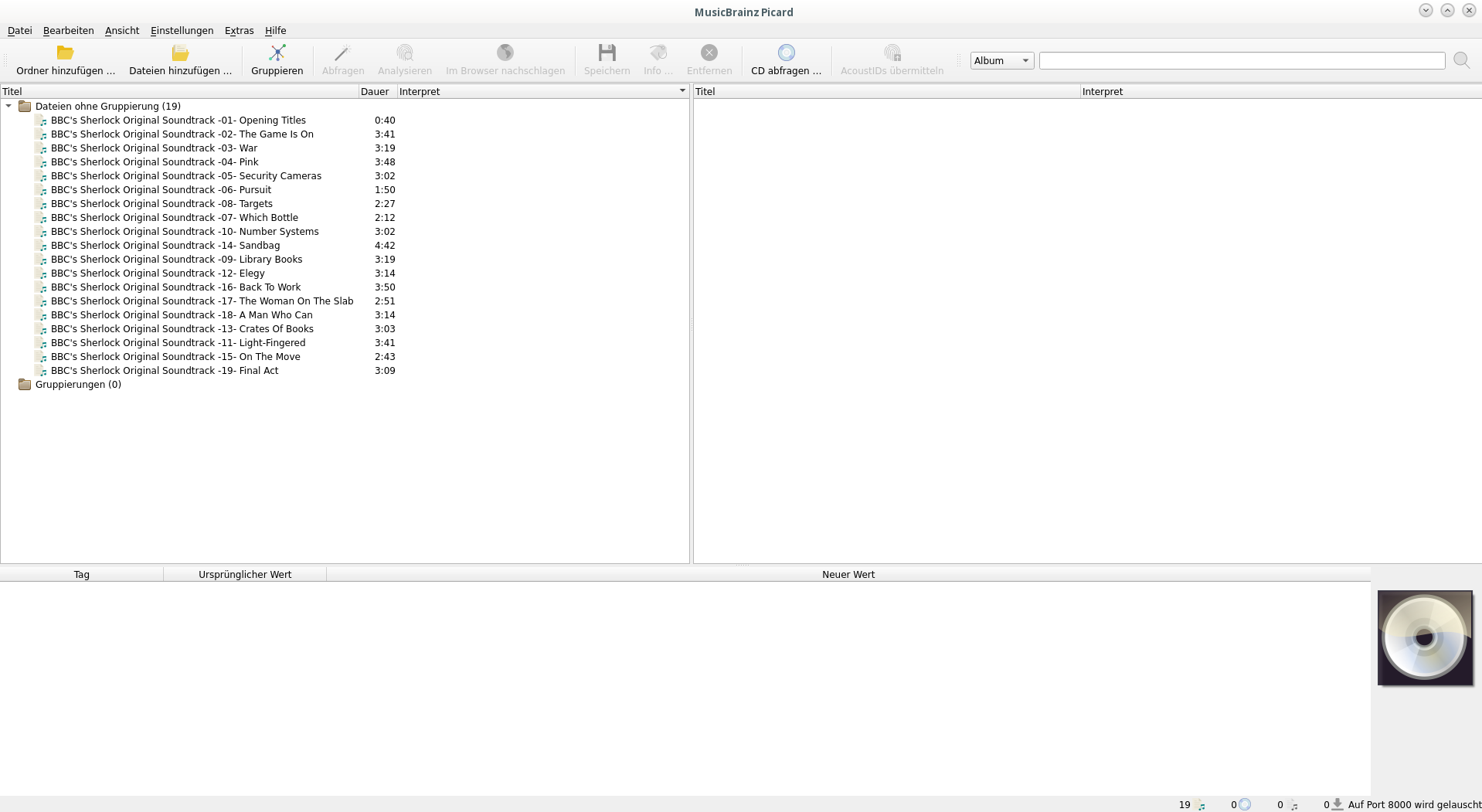
MP3 Files oder ganze Ordner hinzufügen.
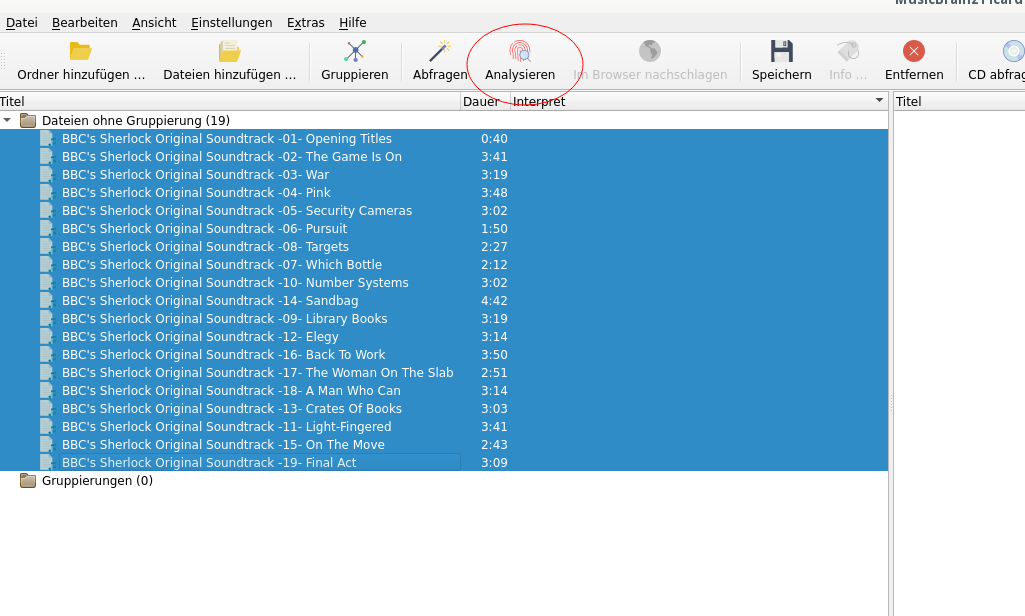
Die Dateien auswählen
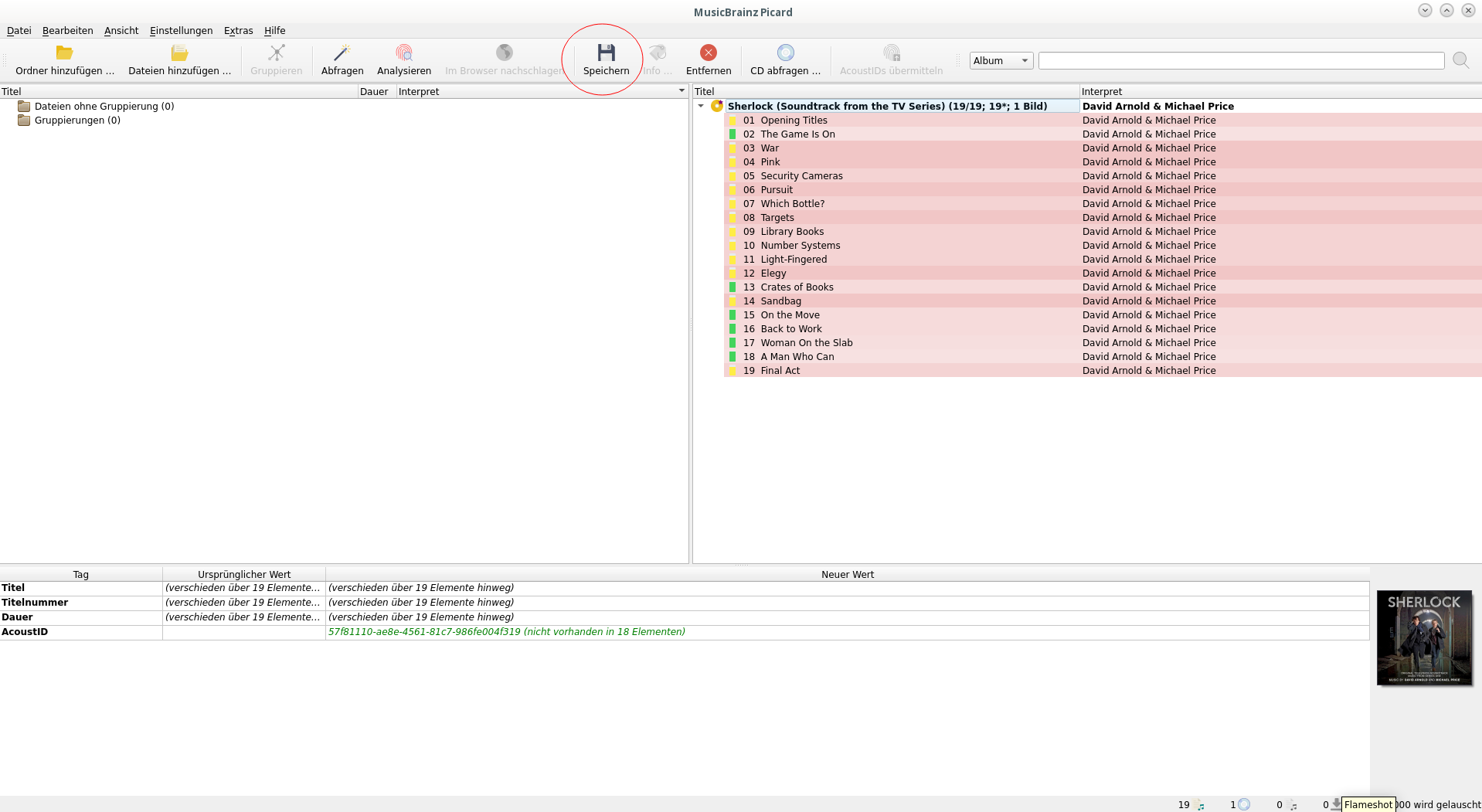
Die Dateien werden mit verschiedenen Wahrscheinlichkeiten erkannt
Noch speichern und wir sind fertig.
Nachdem man mit Picard irgendwann, realistisch so Wochen später, fertig ist, dann erzeugt man einmal die Metadaten mit dem PVA Befehl „erneuere metadaten“ und danach kann man mit Carola auch nach „SmoothJazz“ suchen, oder was Raghesh sonst noch so gefällt 😉
Termine! Termine, nichts als Termine!
Das Mantra der Postmoderne lautet nicht „Können Sie mich hören?“ sondern „Nicht schon wieder ein Meeting“. Nun bei der Anzahl der Meetings kann Carola zwar nicht helfen, aber bei der Organisation könnte sie jetzt hilfreich werden:
„Carola erinnere mich am Dienstag um achtzehn Uhr dreißig an Linux am Dienstag“
Der obige Satz führt dazu, daß Carola „Linux am Dienstag“ in die Termindatenbank aufnimmt und einen am nächsten Dienstag um 18:30 Uhr an unseren Treff „Linux am Dienstag“ erinnert. Genauso gut kann man den Tag weglassen oder „morgen“, „Übermorgen“ usw. verwenden. Da die Woche nur 7 Tage hat, können wir so nur rund eine Woche abdecken. Die Angabe des Datums fehlt noch. Der Satz:
„Carola erinnere mich um achtzehn Uhr dreißig an Linux am Dienstag“
ist auch völlig valide und meint implizit HEUTE ABEND um 18:30 Uhr.
„Carola meine Termine bitte“ oder etwas unhöflicher „Carola meine Termine“ führt dann zu einer sprachlichen Auflistung der Termine. Löschen kann man die Termine noch nicht, da die Analyse des Datums im Code noch fehlt.
„Computer?“
Wem Carola als Name nicht gefällt, oder jemand einfach das vollständige Star Trek Feeling haben will, der kann den PVA jetzt per Befehl umbenennen 🙂
„Carola Dein neuer Name lautet computer“
Gleich danach hört Euer PVA auf den Namen „Computer“. Auf Spielchen mit „Siri“,“ok Google“ oder „Hallo Alexa“ würde ich verzichten, das beeindruckt Besucher kein bisschen 😉
Medienplayer wie MPV oder Celluloid
Wer den Artikel über die neue Mediaplayersteuerung noch nicht gelesen hat, der finden den hier:
Carola: Netflix & Mediaplayerkontrolle
Kleiner Ausblick auf die nächsten Tage: Ihr bekommt einen Technikvortrag über Systemd,Timers und JAVA fails 😉