Fedora 33 BETA im Test und es ist nicht so wies sein sollte.
Gnome 3.38: fühlt sich wie ein Rückschritt an
Diverse Probleme plagen Fedora 33 in meinem jüngsten Test. Als Testhardware habe ich mal mein Surface Pro 4 benutzt, was ich besser gelassen hätte, denn Fedora 33 bootet nicht vom USB Stick, oder doch? Mögliche Antworten: Ja / Nein / Vielleicht und alle sind korrekt :(((
Über das letzte Wochenende habe ich mir mit dem Jungs von der Fedora-Mailingliste einen Debugmarathon gegönnt, nur leider komplett erfolglos.
Steckt man den USB Stick mit Fedora 31 ins Laufwerk, ist ein Booten problemlos möglich, egal wie und wann man den Stick reinsteckt. Mit Fedora 33 geht das nicht mehr. Steckt man den Stick rein, startet die Hardware, wechselt ins Bios und bootet dann von USB, gibt es nur einen Reset. Steck man den Stick erst ein, wenn man schon im Bios ist, dann geht’s 😐 Das macht natürlich wenig Hoffnung, wenn das Gerät bald aktualisiert werden muß.
Wir haben den Grubbootloader ersetzt, die Biosbootconfig in 3 Sekunden zerstört, in 3h wiederhergestellt, und am Bootverhalten vom Surface änderte sich bezüglich Fedora 33 nichts. Es geht einfach nicht und Debuggen geht auch nicht, weil was willste da debuggen, wenn das System einen Instantreset macht? Wir tippen auf Firmwarefehler im EFI Bios des Surface, aber da kein Windows mehr drauf ist, wo sollte das Update dafür herkommen?
Aber, ich habe ne Menge über die Grubkonsole gelernt! Auch das die Anleitung von Fedora zum Recovery nicht funktionieren 🙁
Wenn es denn bootet..
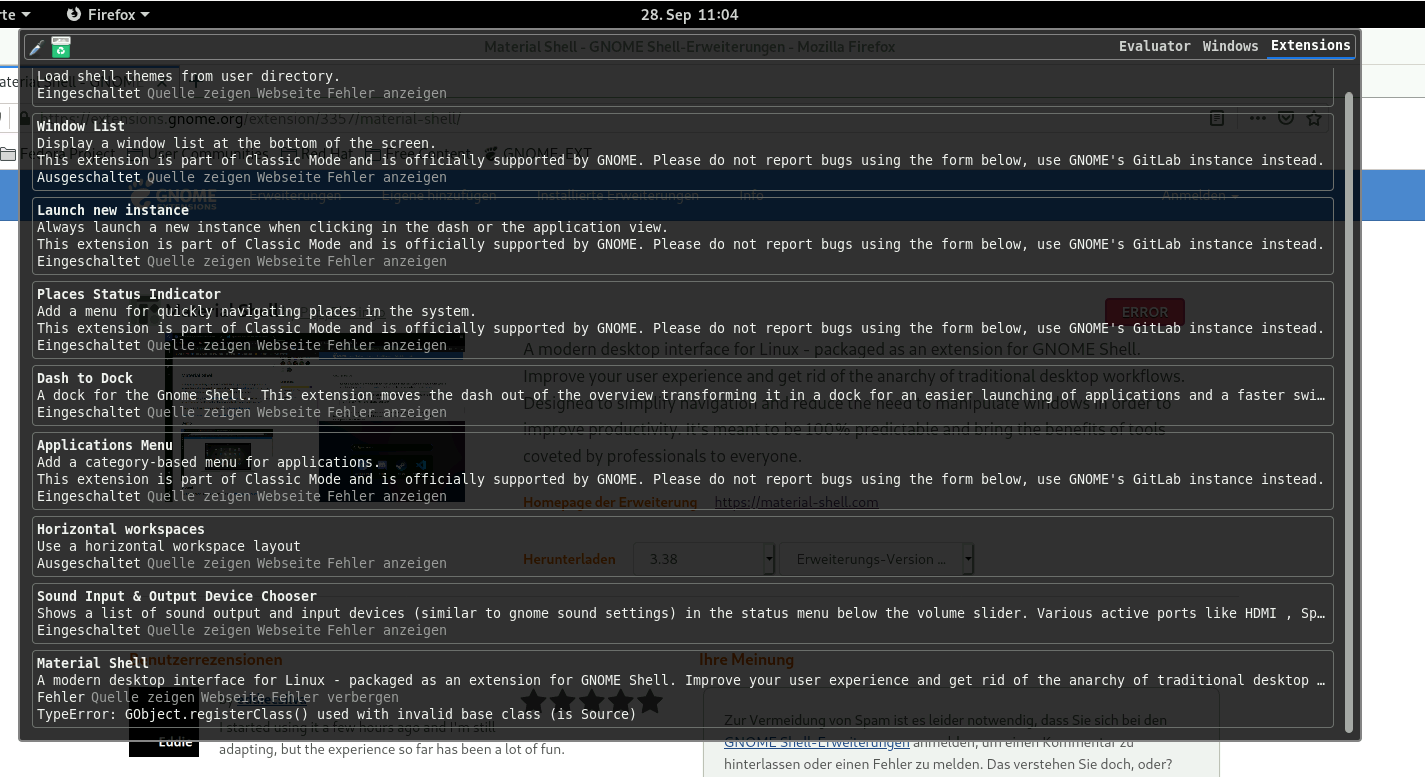
… kommt man zum neuen Gnome 3.38 Desktop. Ich konnte zwar die neuen Monitoranordnung nicht testen, aber ansonsten ist es fast unverändert. Was einen Tabletbenutzer so richtig nerven wird, ist das neue Ausklappmenü zum Abmelden und Abschalten des Rechners.
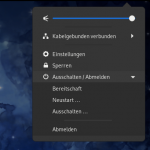 Was für ein SCHEISS! Sind wir ernsthaft wieder in den Neunziger Jahren angekommen?
Was für ein SCHEISS! Sind wir ernsthaft wieder in den Neunziger Jahren angekommen?
Was soll sowas? Hat wirklich jemand unabsichtlich auf „Bereitschaft“ gedrückt oder versehentlich das Neustarticon nicht gefunden?
Ich glaube kaum, also warum in zum Geier ändert man das von ONE-Click in ein CLICK-MOVE-CLICK System????
Es war doch schon perfekt 🙁
Probleme mit Videokonferenzen
Was jetzt kommt ist eine alter Hut: Wayland ist noch nicht fertig! Party ! Jubbel ! Heiterkeit ! … moment.. nicht fertig? Aber es geht doch!?!? Nein, tut es doch nicht.. Screenrecording geht nicht:
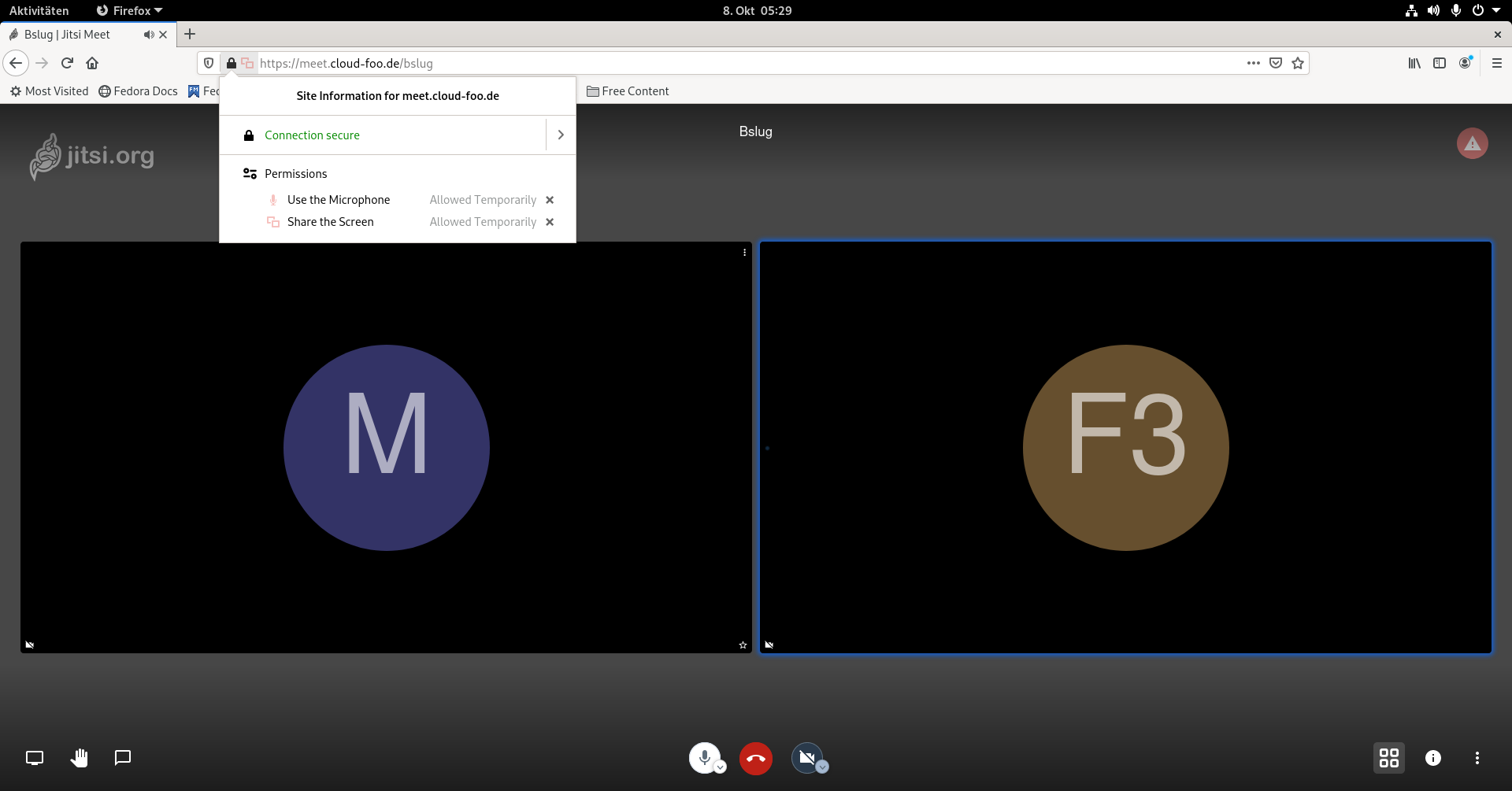 Wie man in diesem Screenshot sehen kann, sieht man nicht außer einem schwarzen Bildschirm, obwohl Firefox ( siehe oben ) den Bildschirm teilt. Wenn man das nicht in einer VM ( Screenshot ) sondern auf einer HW ( Surface Pro ) macht, dann ist auch das Jitsi Meet Icon links unten in der Ecke passend markiert, weil er wirklich Schwarzbilder streamt. Einfach selbst testen.
Wie man in diesem Screenshot sehen kann, sieht man nicht außer einem schwarzen Bildschirm, obwohl Firefox ( siehe oben ) den Bildschirm teilt. Wenn man das nicht in einer VM ( Screenshot ) sondern auf einer HW ( Surface Pro ) macht, dann ist auch das Jitsi Meet Icon links unten in der Ecke passend markiert, weil er wirklich Schwarzbilder streamt. Einfach selbst testen.
Das nächste Desaster naht
Wenn man jetzt LUG Mitgliedern die neuen Sachen wie ZRAM, BttrFS zeigen will, geht das nicht, also muß man kreativ werden:
Überlegung: Installiere XRDP, lege User an, Verbinde Dich mit User auf RDP und zeige Ihm einfach alles, indem Du von Deinem Desktop z.b. xFreeRDP oder Remmina überträgst … Tja.. was soll ich sagen.. wie wärs mit „Ein Bild sagt mehr als tausend Worte“ …
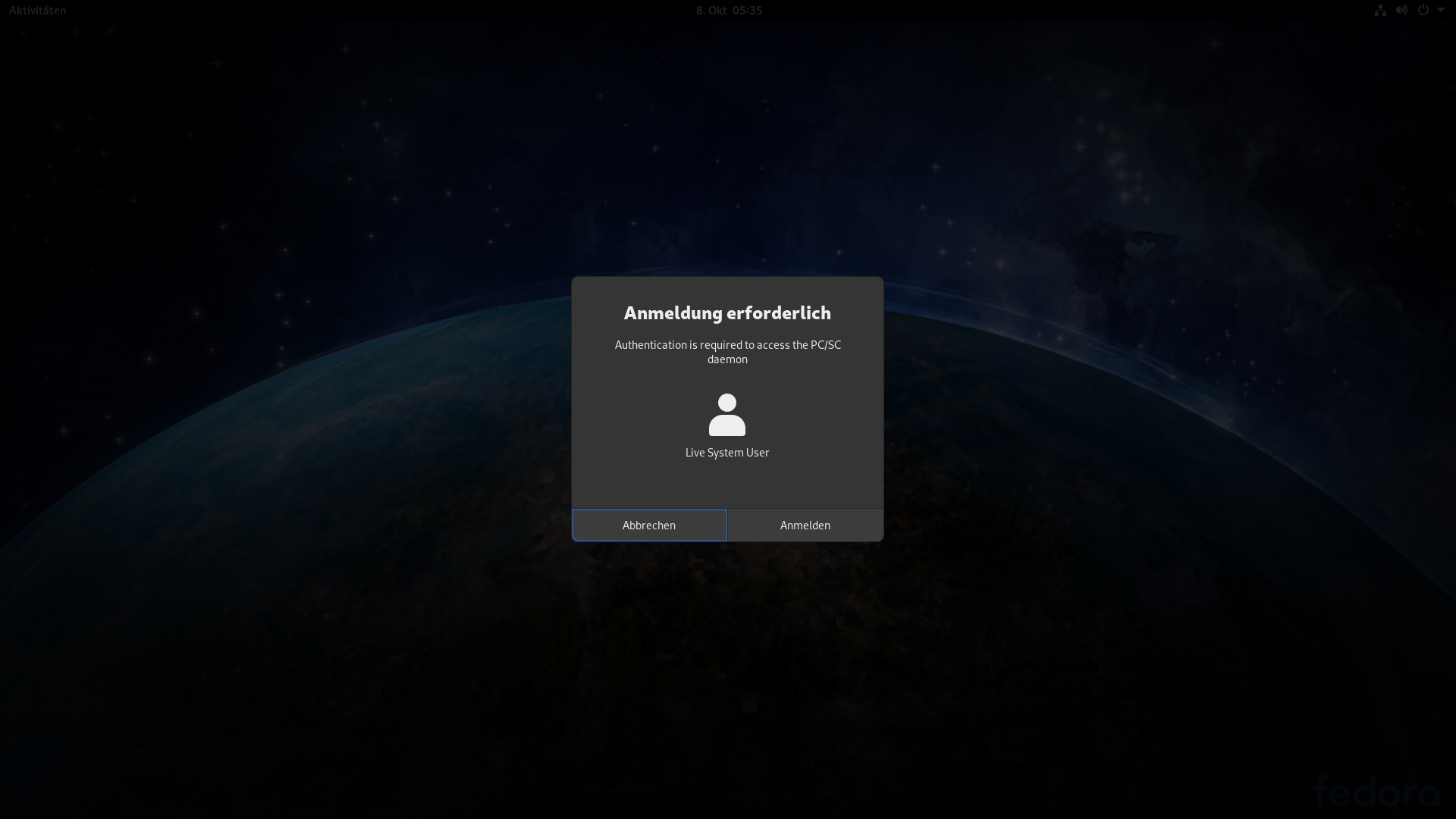 Und dann steht Ihr da mit Eurem RDP Desktop der NUR NOCH diese Abfrage anzeigt, die man zwar beenden kann, die dann aber in der nächsten ms wieder aufpoppt!
Und dann steht Ihr da mit Eurem RDP Desktop der NUR NOCH diese Abfrage anzeigt, die man zwar beenden kann, die dann aber in der nächsten ms wieder aufpoppt!
Abrechen => Endlosslooping
Anmelden => neuer Requester mit anderem Text, aber den gleichen zwei Buttons!
Keine Eingabemöglichkeit!
Wie soll man da ein Passwort für einen User eingeben, der gar kein Passwort hat ????
Aus der Nummer kommt man nicht mehr raus, ergo muß man die RDP Session beenden und ALLE PROZESSE des eingeloggten Benutzers als Rootuser KILLEN. Das errinnert mich stark an ein Scherzprogramm aus den 90zigern.. hmm, wieder die 90ziger.. ein Muster deutet sich an 😉
Natürlich gibt es eine Ursache und eine Lösung, aber die Situation sollte gar nicht erst auftreten.
Ursache: pcsc-lite und Konsorten! Ein SmartCard-Service … auf einem Gerät ohne einen SmartCardreader!
Wie dämlich ist das, daß der sich dann auch noch so startet, obwohl er mit nichts arbeiten kann?
Schritt 1 eines SmartCardDaemons wäre festzustellen, welchen SmartCardreader er benutzen soll.
Schritt 2 eine Fehlermeldung ausgeben, weil er keinen gefunden hat.
Aber sicher nicht in einer Endlosschleife ohne Abbruchbedingung sinnlos Leute ärgern, seit JAHREN SCHON!
Lösung
Falls Euch das mal betreffen sollte, denn ich habe so meine Zweifel, daß andere Distris da besser abschneiden:
systemctl stop pcscd;systemctl disable pcscd
killall -9 pcscd
dnf erase pcsc* -y
und weg damit. Viel Spaß, falls Ihr RDP und SmartCards zusammen benutzen müßt. Schreibt mal eine Karte, wenn Ihr den Ort gefunden habt, wo das zusammen funktioniert 😉
Mal sehen was die Jungs von der Liste dazu sagen, weil die User-Experience, die ja so wichtig ist, mal direkt lang auf die Nase gefallen ist.
ZRAM
ZRAM läuft.. aber irgendwie merkt man nichts.. 2 GB RAM sind 2 GB RAM. Tja.. da braucht es wohl erst einmal mehr um überhaupt damit arbeiten zu können.
Bttrfs habe ich nicht ausprobiert, ich habe ja schon funktionierende Festplatten mit einem OS drauf 😉