\o/ Alles Gute zum Bürzeltag, Linux! \o/
Auf das Du ewig jung bleibst,
weiter wächst und gedeihst,
uns niemals entgleist,
und uns nie hintertreibst.
Prost!
Der (IT) Blog aus Braunschweig
Auf das Du ewig jung bleibst,
weiter wächst und gedeihst,
uns niemals entgleist,
und uns nie hintertreibst.
Prost!
Als Gastbeitrag gibt es heute einen Erfahrungsbericht von Malte ( BSLUG) zum Dell Venue 8 Pro Tablet und wie sich das mit Linux so schlägt. Da das Gerät schon in die Jahre gekommen ist, kann ich Euch leider nur Link zu Nachfolger anbieten: dell-venue-11-pro.
Ich klinke mich hier aus und wünsche Euch viel Vergnügen mit Maltes Abenteuerbericht:
Von der Begeisterung der Surface-Fraktion angesteckt, hatte ich irgendwann im Frühjahr beschlossen, mir auch ein Tablet anzuschaffen. Was ich wollte, war aber weniger ein Laptop-Ersatz (der funktioniert noch), als überhaupt mal ein Tablet auszuprobieren. Achtung, der Artikel wird lang…
Nach etwas Suche habe ich mich dann für das Dell Venue 8 Pro (5830) von 2013/14 entschieden. Von Werk aus ist ein „richtiges“ Windows 8 vorinstalliert. Das ist wichtig, weil das Tablet dank Intel-Prozessor technisch gesehen eher ein geschrumpftes Note- bzw. Netbook ist als ein aufgeblasenes Handy (wie die meisten Android-Tablets).
Das Tablet habe ich mit Hülle und Ladegerät für 60€ ersteigert, einen passenden Eingabestift für knapp 40. Damit ist mein Experiment „Tablet“ in Summe gerade noch unter 100€, viel besser für mein studentisches Budget als ein Surface. Außerdem, 100€ ist für „Spielzeug“ noch vertretbar.
Leistungsmäßig darf man aber vom 2-Watt-Atom keine Wunder erwarten, und der Mangel an Anschlüssen (eine SD-Karte und eine Micro-USB-Dose, immerhin mit OTG-Support), RAM (2 GB) und ROM (32 GB) ist grenzwertig. Dafür ist das Tablet dünn und leicht (8 Zoll), und hält trotz Gebrauchtgerät je nach Nutzung 4-6 Stunden durch.
Wenn der Stift (Eigenentwicklung von Synaptics) mal funktioniert, dann ist er ganz okay, aber nicht mit Wacom oder N-Trig (z.B. im Surface) zu vergleichen. Man sollte darauf achten, einen Stift aus der 2. Serie zu bekommen (silber-schwarz statt nur schwarz), die erste war laut Internet häufig fehlerhaft. Meiner gab aber auch leider nach einigen Monaten intensiver Nutzung mit mechanischem Defekt auf. Wer weiß, wie man die silber-schwarze Version auf bekommt, soll sich bitte melden, im Internet ist nichts zu finden…
Immerhin hat Dell dem Tablet ein richtiges, klassisch grau-blaues BIOS spendiert. Das sieht zwar mit Touch etwas komisch aus, ist aber im Vergleich zu anderen Tablets extrem hilfreich.
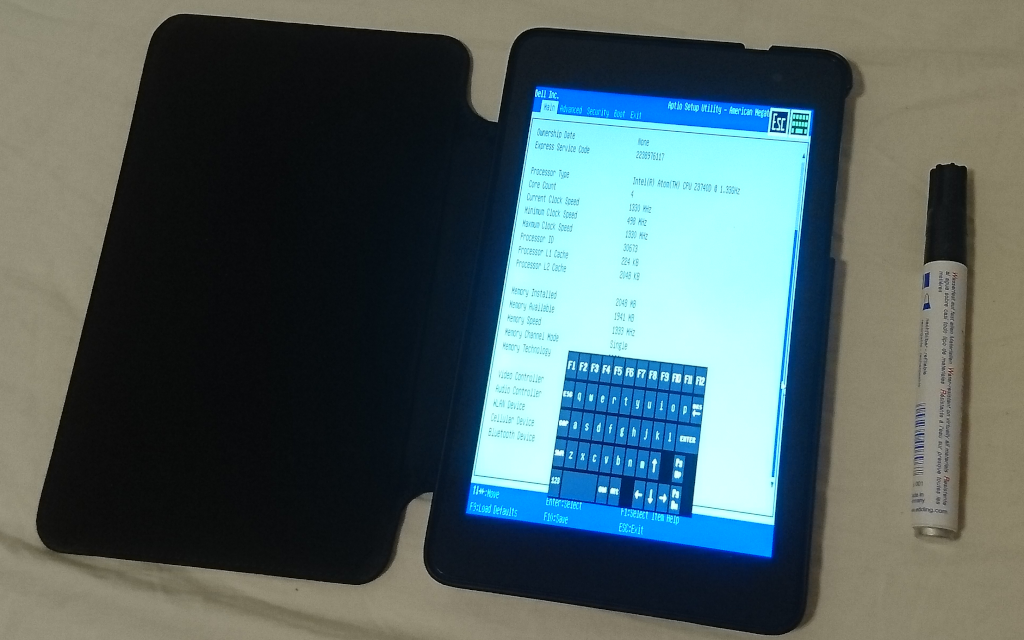
Aussehen und Bios – Stift nur zum Größenvergleich. Diesen Stift bitte nicht benutzen 😉
Nachdem ich etwas mit dem installierten Windows gespielt (und ein Backup gemacht) habe, muss auf das Gerät zumindest mal auch Linux drauf, sonst wäre es ja hier auf dem Blog fehl am Platz 😉
Fangen wir mal an mit dem, was geklappt hat: Linux läuft mit aktuellem Kernel (5.x) in der Regel stabil, erkennt Lage, Helligkeit, Video, Audio, Stift und nach Download der Firmware auch WLAN, und ist allgemein benutzbar. Je nach Distribution (z.B Fedora 29) ist die Installation genau so einfach wie auf einem Laptop: mit OTG-Adapter vom USB-Stick starten (Lautstärke-Wippe für Bios- bzw. Bootmenü) und Anweisungen folgen.
Die einzige richtig benutzbare Desktopumgebung für Touch ist Gnome 3. Punkt.
Korrigiert mich hier bitte, ich habe nichts besseres gefunden. Aber Gnome 3 ist LANGSAM. Das merkt man schon auf einem Desktop mit i5 und massig RAM, und das wird mit 2 GB RAM und einem 2-Watt-Prozessor nicht besser.
Einer der Gründe ist wohl, das Gnome mehr oder weniger ALLES in einem Thread erledigt. Unter Wayland beinhaltet das sogar Input-Events – wenn also gerade eine Animation „läuft“ bzw. kriecht, reagieren weder Maus noch Touch noch Tastatur. Bei Touch sorgt das für leichte Aggressionen, weil dann einfach „Dinge passieren“. Unter X11 reagiert wenigstens noch die Event-Verarbeitung. Mit dem RAM-Verbrauch von Gnome will ich erst gar nicht anfangen, sonst bin ich morgen noch nicht fertig.
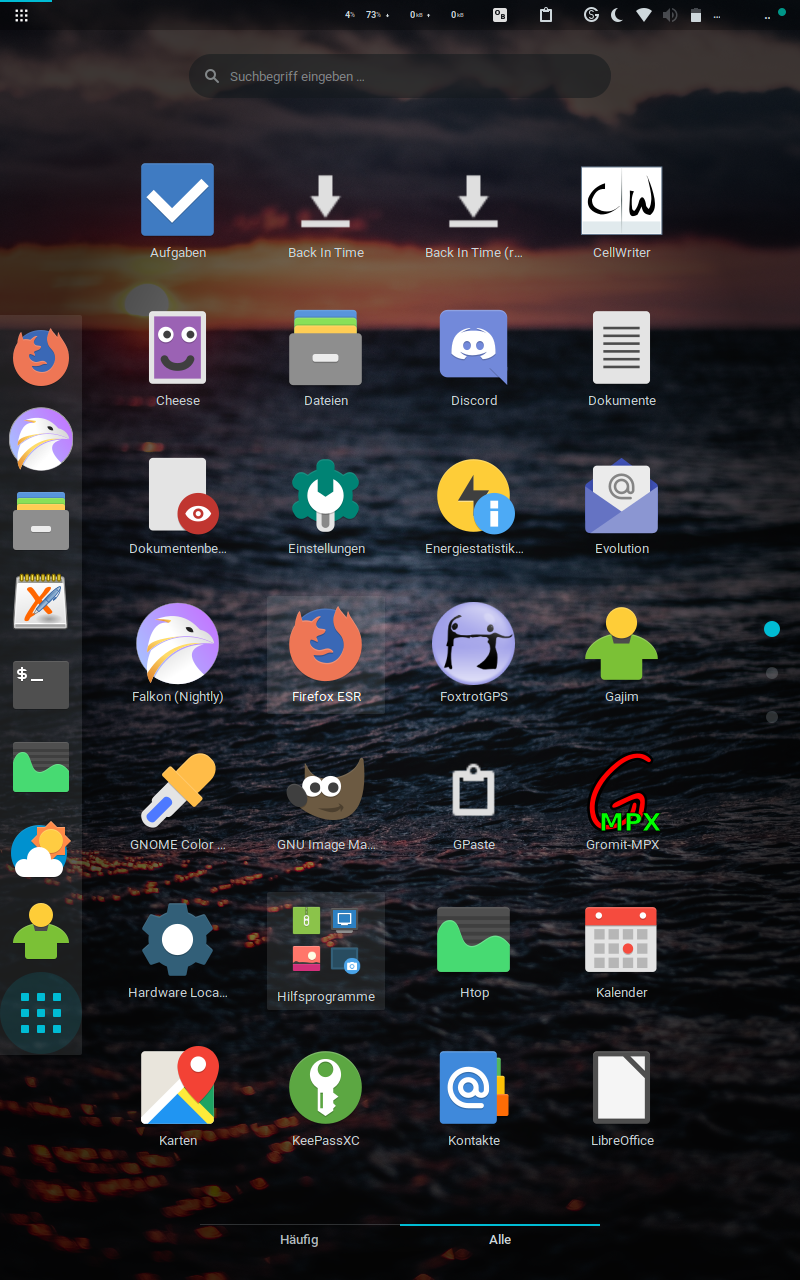 |  |
| Screenshots aus dem Betrieb, Gnome 3 mit Theme und Iconpack | |
KDE oder Cinnamon zeigen, dass es definitiv anders geht, sind aber mit Touch (noch) nicht vernünftig zu benutzen. Selbst Windows 10 war da schneller… wenigstens sieht Gnome mit den vielen verfügbaren Themes gut aus.
Hardwareunterstützung bei weniger bekannter Hardware ist unter Linux oft ein Problem, und so auch bei meinem Tablet: Es gibt es keinen passenden Kamera-Treiber für Linux (Stichwort „atomisp“), und der WLAN-Treiber für Linux kann weder Bluetooth, 5 Ghz oder gar Miracast. Gerade Miracast wäre für ein Gerät, was keinen Bildschirmanschluss hat, extrem nützlich. Als Workaround habe ich etwas mit Remote-Desktop von einem PC aus gebastelt, aber schön ist das nicht. Auch hat das WLAN Probleme mit dem Stromsparen: um unter Linux Paketverluste und eine Latenz von 400 ms (!) im lokalen Netz zu vermeiden, muss man hier eine gut versteckte Konfigurationsdatei ändern.
Auch nicht schön: Der Linux-Kernel auf einigen billigen Intel-Prozessoren läuft immer noch nicht stabil, das heißt, je nach Tagesform gelegentlich ein Total-Einfrieren. Kernel 5.2 sollte eigentlich Besserung bringen, ist aber auch nicht stabiler. Vielleicht ändert sich hier aber noch etwas.
Weiter haben die Live-USB-Sticks vieler Distributionen in der 64-bit-Version ein Problem mit der Kombination 32-bit EFI und 64-bit CPU (lassen sich aber, einmal gestartet, korrekt installieren). Löbliche Ausnahme ist hier Fedora. Hut ab 😉
Ärger gab es auch mit Firefox. Um unter X11 (mit Gnome deutlich schneller als Wayland, s.o.) mit Touch wie vom Handy gewohnt bedienbar zu sein (mit dem Finger scrollen, 2-Finger-Zoom, Rechtsklick etc.), muss man erst mal an geeigneter Stelle die Umgebungsvariable MOZ_USE_XINPUT2 auf 1 setzen.
Toll ist auch, dass Firefox unter Linux keine Hardware-Beschleunigung für Videos nutzt. Damit wird der arme Atom-Prozessor bei Youtube und Verwandtschaft in HD zur Heizplatte. Den entsprechenden Bugreport gibt es jetzt schon ein paar Jahre, aber das scheint keinen zu interessieren. Um trotzdem außerhalb des Kühlschranks Youtube schauen zu können, habe ich ein FF-Addon namens „ff2mpv“ ausgegraben, was mit etwas Tricksen dazu gebracht wurde, mit mpv in 720p mittels GPU zu spielen ( mpv –hwdec=vaapi –vo=vaapi –ytdl-format=“mp4[height<=720]“ $* ) – absolut intuitiv, oder?
Als Alternative zu Firefox sollte man übrigens mal Falkon (früher QupZilla) ausprobieren, der Touch-Support ist dank Chromium/QtWebEngine-Unterbau fast genau so gut und der schlanke Browser ist gefühlt etwas schneller. Nachteil ist die kleine Community und die fehlenden Addons.
Ich habe das Tablet jetzt einige Monate mit dem Stift als Papierersatz in Vorlesungen und zu Hause benutzt, nutze das daneben zum Videos-auf-dem-Sofa-oder-im-Zug schauen oder zum Schnell-mal-etwas-suchen. Dafür hat es die perfekte Größe. Würde ich das nochmal kaufen müssen, würde ich mich wahrscheinlich für die 11-Zoll-Version entscheiden, 8 Zoll ist doch recht knapp.
Neben Fedora habe ich eine Reihe Distributionen ausprobiert, von denen aber eigentlich alle irgendeine Macke hatten. Hängen geblieben bin ich bei Debian, weil ich das einerseits auch auf dem Laptop habe und andererseits die etwas ältere Gnome-Version subjektiv etwas flüssiger läuft.
Das Tablet ist zwar kein Laptop-Ersatz, aber fühlt sich deutlich mächtiger an als ein noch so smartes Handy. Wer das nicht glaubt, der soll mal versuchen, auf Android z.B. mal mehrere Fenster gleichzeitig auf zu machen… oder mir sagen, wann sein Androide das letzte Mal ein Kernel-Update bekommen hat.
Trotz allem, für Leute, die das Gerät „einfach nur nutzen“ wollen, bleibt zumindest bei diesem Tablet nur Windows, so leid mir das tut.
Auch wenn der Artikel ziemlich negativ klingt: Letztlich war das Experiment „Tablet“ mindestens ein Teilerfolg. Einmal habe ich das Gerät gerade auch zum Basteln gekauft, war also nicht überrascht. Zum anderen, wenn ich mir das nächste Mal einen Laptop kaufe, wird er wohl mindestens auch Touch haben.
Xournalpp (https://github.com/xournalpp/xournalpp/) zum Schreiben und Zeichnen, muss man je nach Distribution ggf. leider selbst kompilieren, ist es aber gegenüber dem „normalen“ Xournal wert
Onboard (https://launchpad.net/onboard) als viel (!) bessere Tastatur mit konfigurierbarem Layout
Easystroke (https://github.com/thjaeger/easystroke/wiki) für erweiterte Gesten („wenn ich einen Kringel mit dem Stift male, dann…“)
https://www.studioteabag.com/science/dell-venue-pro-linux/ extrem hilfreicher Artikel zu Linux auf dem Venue 8 Pro, englisch, leicht veraltet
ff2mpv (https://addons.mozilla.org/de/firefox/addon/ff2mpv/) Um Online-Videos mit mpv hardwarebeschleunigt abzuspielen
Und noch der Beitrag zum Wifi-Powersaving im Networkmanager:
https://gist.github.com/jcberthon/ea8cfe278998968ba7c5a95344bc8b55
NetworkManager supports WiFi powersaving but the function is rather undocumented.
From the source code: wifi.powersave can have the following value:
Then I propose 2 files, only one of them needs to be put under /etc/NetworkManager/conf.d/.
One is forcing to disable powersaving, while the other one enable it.
Once you have put the file in the right folder, simply restart NetworkManager:
sudo systemctl restart NetworkManager
| # File to be place under /etc/NetworkManager/conf.d | |
| [connection] | |
| # Values are 0 (use default), 1 (ignore/don't touch), 2 (disable) or 3 (enable). | |
| wifi.powersave = 2 |
| # File to be place under /etc/NetworkManager/conf.d | |
| [connection] | |
| # Values are 0 (use default), 1 (ignore/don't touch), 2 (disable) or 3 (enable). | |
| wifi.powersave = 3 |
~ Malte
So, es ist wieder soweit, wir stopfen den Exim gegen CVE-2019-15846. Diese Lücke beinhaltet einen eher ungewöhnlichen Angriffsvektor, jedenfalls für mich. Aus der Richtung hätte ich nicht mit Problemen gerechnet.
Was ist das Problem werdet Ihr fragen? Schon mal was von TLS gehört? Nein? Nagut 😉 Das ist der Nachfolger von SSLv3 und wurde 1998 ins Leben gerufen um primär ein Problem zu lösen: Für SSLv3 braucht jede Domain, die das benutzen wollte, eine eigene IP auf dem Server, weil es nicht möglich war, das Cert passend zur aufgerufenen Domain auszuwählen.
Dies wurde durch SNI in TLS 1.0 behoben, so daß Webserver jetzt alle verschlüsselt erreichbaren Domains auf einer einzigen IP hosten konnten. Dazu gibt der Client, dem Web/ oder Mailserver mit, für welche Domain er eine Verbindung aufbauen möchte, bevor die Verbindung wirklich aufgebaut wird.
Der per SNI übergebene Domainname landet beim Exim derzeit ungeprüft im Filesystem und wenn etwas ungeprüft im Filesystem landet, kann man damit einiges anstellen, in diesem Fall Root werden. Das ist eine stark vereinfachte Darstellung, weil ich will ja nicht, daß Ihr Euch daraus einen eigenen Exploit baut 😉
Mal von den bereits verfügbaren Update-Patchen abgesehen, kann man den Angriff dadurch erschweren, daß man die zum Angriff nötigen Zeichen im SNI blockiert.
Das geht so :
acl_check_mail:
deny condition = ${if eq{\\}{${substr{-1}{1}{$tls_in_sni}}}}
message = no invalid SNI for you
deny condition = ${if eq{\\}{${substr{-1}{1}{$tls_in_peerdn}}}}
message = no invalid tls strings for youEs wird aber empfohlen das Update einzuspielen, weil nicht ausgeschlossen werden kann, daß dies nicht ausreicht um die Lücke dauerhaft zu schließen.
Für den derzeit bekannten Angriffsvektor gibt es bereits einen Proof-of-Concept Exploit, daher solltet Ihr sehr schnell handeln und noch schneller Updaten!
Das ist dem schnell Updaten wird für Redhat und Fedora Benutzer ein Problem werden, denn es gibt noch keine Updates. Fedora/Redhat hat es komplett verpennt, obwohl ich dem Maintainer höchstselbst eine Headsup Notitz gemailt habe und auf einer von den Distros überwachten Liste, eine entsprechende Nachricht eingegangen ist. Da haben ich und Golem das ja auch her gehabt. Heise Sec meinte, es würde reichen, wenn man das CERT bei Twitter abboniert hat.. ne sorry, reicht nicht 😀
Dann fixt jetzt mal eure Server, mein Cluster ist damit schon durch.
1. Update: 14:48
Wie aus sicherer Quelle bekannt wurde, hat Redhat eine „Urlaubsvertretung“ mit dem Problem betraut, da der Maintainer nicht zur Verfügung steht derzeit, er ist im Urlaub. Ob das die Ursache ist, daß es noch keine Updates gibt, weiß man nicht sicher, aber im Bereich des möglich wärs ja 😉 Sorry Fedora, aber ein bisschen Spot muß sein, ich sehe nämlich immer noch keine Pakete im Buildsystem bauen …
2. Update: 17:11
Das Update von Exim hat jetzt bei Fedora den Status „dringend“/“urgent“ .
3. Update: 18:20
TestRPMs sind verfügbar:
https://kojipkgs.fedoraproject.org//packages/exim/4.92.2/1.fc29/x86_64/exim-4.92.2-1.fc29.x86_64.rpm https://kojipkgs.fedoraproject.org//packages/exim/4.92.2/1.fc29/x86_64/exim-mysql-4.92.2-1.fc29.x86_64.rpm https://kojipkgs.fedoraproject.org//packages/exim/4.92.2/1.fc29/x86_64/exim-clamav-4.92.2-1.fc29.x86_64.rpm
4. Update: 19:01
Die RPMs wurden ins Stable gepusht. Damit gehen die Updates jetzt für alle live.
Danke an alle Helfer, Urlauber, Urlaubsunterbrecher und Vertretungen, die es heute Nachmittag dann doch noch geschafft haben und besonders an Heiko Schlittermann, mit dem ich noch die Eckpunkte des Workarounds diskutieren konnte, bevor es offiziell wurde.