Einen Fall von Load 200 bei einem Idlefaktor von 96% sieht man nicht alle Tage, also schauen wir uns den mal an wie das mit NFS zusammenhängt 😉
Fedora: nfs-utils 2.5.4 nicht funktional
Schreck in der Morgenstunde: „Email vom Server : Load 100+“ Da hatte ich schon eine böse Vorahnung, daß ich per SSH nicht mehr in diesen Server reinkomme und den Hart rebooten muß. Ihr könnt Euch vorstellen, daß ich sehr überrascht war, als der Login flott und ohne Probleme ablief. Ein Blick in TOP und die Load zeigte tatsächlich 111 an. Etwas später waren es 150, dann 180 und irgendwann wurde die 200 durchbrochen (vermutlich), aber da habe ich nicht mehr hingesehen 😉
Jetzt ist das ein sehr bizarres Bild, wenn man eine Load von 180 im Top sieht, aber nur einen Prozess mit 10% CPU Last überhaupt arbeiten will. Die Load beschreibt das Verhältnis von cpuwollenden Prozessen zur Anzahl der Kerne einer CPU, was voraussetzt, daß es Prozesse mit CPU Verbrauch gibt, gab es aber nicht 😀
Also schauen wir uns pstree an, jede Menge Prozesse, aber nichts steht, alles arbeitet „normal“. Und dann stehst Du da als Admin und verstehst die Welt nicht mehr: Load 180+, die CPU langweilt sich zu Tode, und alle CronJobs und Services ( Web, FTP, Mail etc. ) laufen wie am Schnürchen.
Bevor ich das auflöse, gebe ich den erfahrenen Admins Gelegenheit das nochmal zu durchdenken 🙂
5
4
3
2
1
Auflösung
NFS
Ok, ich kann Eure Gesichter jetzt förmlich sehen 🙂 Ich habe es auch nur durch Zufall gefunden, weil … Trommelwirbel … es im /var/log/messages einen Hinweis gab, daß gegen 6 Uhr morgens ein NFS Server nicht reagiert hat. Es war also nicht einmal der Server mit der Load der das Problem hatte, sondern der Fileserver 😉
Der NFS Mount funktionierte nicht mehr, wurde aber via Webserver Repository regelmäßig von allen Servern im Cluster mit Anfragen bombardiert, ob es neue Pakete gibt. Jede dieser Anfragen erzeugte einen „httpd“ Prozess, der aber keine Leistung ziehen konnte, es aber wollte, weil die IO zum Fileserver stillstand. Jetzt fallen ein paar mehr httpd Prozesse auf einem Webserver nicht wirklich auf.
So, damit war geklärt wieso wir eine Load von knapp 200 hatten, aber wieso ging der Mount nicht mehr?
Kurz ein paar Grafiken und Zahlen für Euch:

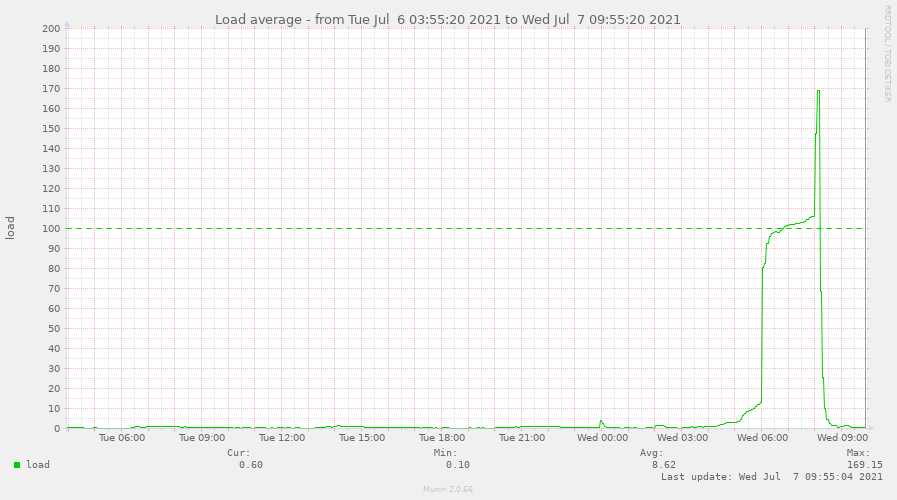 Der Graph wird nur alle 5 Minuten erzeugt, daher die leicht abgeflachte Spitze
Der Graph wird nur alle 5 Minuten erzeugt, daher die leicht abgeflachte Spitzeund so sah das in Zahlen aus, minütlich ab 07:07:2021-08:02:01:
LOAD: 128.25 112.19 107.39 12/1536 3283086
LOAD: 162.90 124.62 111.94 12/1597 3283496
LOAD: 182.58 137.25 117.08 13/1608 3283850
LOAD: 190.78 147.84 121.98 16/1598 3284211
LOAD: 194.96 156.89 126.72 9/1582 3284999
LOAD: 195.70 164.04 131.06 14/1661 3285411
LOAD: 195.92 169.87 135.14 11/1649 3285732
LOAD: 196.50 174.77 139.00 10/1659 3286091
LOAD: 180.98 175.53 141.56 23/899 3286449
LOAD: 67.34 143.85 132.80 12/846 3287234
LOAD: 25.92 117.98 124.59 14/859 3287613
LOAD: 11.42 97.05 116.97 11/856 3287959
Das NFS UPDATE
Vor ein paar Tagen gab es ein NFS Update:
2021-07-07T04:01:45+0200 SUBDEBUG Upgrade: libnfsidmap-1:2.5.4-0.fc33.x86_64
2021-07-07T04:01:45+0200 SUBDEBUG Upgrade: nfs-utils-1:2.5.4-0.fc33.x86_64
2021-07-07T04:01:46+0200 SUBDEBUG Upgraded: nfs-utils-1:2.5.3-2.fc33.x86_64
2021-07-07T04:01:46+0200 SUBDEBUG Upgraded: libnfsidmap-1:2.5.3-2.fc33.x86_64
was zu diesem Resultat führte:
# systemctl status nfs-mountd
● nfs-mountd.service – NFS Mount Daemon
Loaded: loaded (/usr/lib/systemd/system/nfs-mountd.service; static)
Active: failed (Result: exit-code) since Wed 2021-07-07 09:20:22 CEST; 9s ago
Process: 4925 ExecStart=/usr/sbin/rpc.mountd (code=exited, status=0/SUCCESS)
Main PID: 4928 (code=exited, status=1/FAILURE)
CPU: 43ms
Jul 07 09:20:22 XXX systemd[1]: Starting NFS Mount Daemon…
Jul 07 09:20:22 XXX rpc.mountd[4928]: Unable to watch /proc/fs/nfsd/clients: No such file or directory
Jul 07 09:20:22 XXX systemd[1]: Started NFS Mount Daemon.
Jul 07 09:20:22 XXX systemd[1]: nfs-mountd.service: Main process exited, code=exited, status=1/FAILURE
Jul 07 09:20:22 XXX systemd[1]: nfs-mountd.service: Failed with result ‚exit-code‘.
Es blieb nur das Downgrade übrig:
dnf downgrade https://kojipkgs.fedoraproject.org//packages/nfs-utils/2.5.3/2.fc33/x86_64/libnfsidmap-2.5.3-2.fc33.x86_64.rpm https://kojipkgs.fedoraproject.org//packages/nfs-utils/2.5.3/2.fc33/x86_64/nfs-utils-2.5.3-2.fc33.x86_64.rpm
Aber danach, lief der NFS Server wieder normal und die Probleme verschwanden.
Emergency Bugreport ist erstellt, ich fürchte Test-Driven-Development gibt es nicht überall 🙁