Ja, das Fedora 43 Update hatte eine spannende Offenbarung für alle Outlook Benutzer zur Folge, von der Microsoft nicht begeistert sein wird.
Outlook hat Emailverbindung nicht verschlüsselt
und das, obwohl SSL/TLS in den Kontoeinstellungen nachweislich aktiviert war.
Aber der Reihe nach… Ende Mai haben wir turnusgemäß unser ServerOS aktualisiert. Dabei wurde Fedora 42 mit Dovecot 2.3.x durch Fedora 43 und Dovecot 2.4.3 ersetzt. Dies erforderte nicht nur eine komplett neue Konfiguration, es verhinderte auch, daß über einen unsicheren Kanal Passwörter in Klartext übermittelt werden.
Wenn jemand das tat gab es in Outllook diesen Fehler zu bestaunen:

„-ERR [AUTH] Cleartext authentication disallowed on non -secure ( SSL/TLS ) connections.“ stammt tatsächlich vom Dovecot. Die kommt, wenn man über Port 110 mit Netcat (oder telnet 😀 ) eine Verbindung aufbaut und „USER“ / „PASS“ direkt da reinschreibt. Das wäre ein Klartextpasswort über einen Klartextport und das mag Dovecot nicht mehr, was gut so ist.
„Wir hatten doch SSL/TLS aktiviert!“
meldeten die Kunden und hatten Recht, es war SSL/TLS bei den Konto aktiviert, nur leider juckte Outlook das nicht, weil als PORT 110 für POP3 eingetragen war, hat Outlook statt einer „Das paßt aber so nicht zusammen Benutzer!„-Meldung einfach NICHTS gemacht und die Verbindung einfach nicht verschlüsselt, weil 110 der Klartextport ist und man für SSL 995 hätte angeben müssen. Beobachtet haben wir bislang nur POP3 Port 110, ich geh aber davon aus, daß es bei IMAP auch ist.
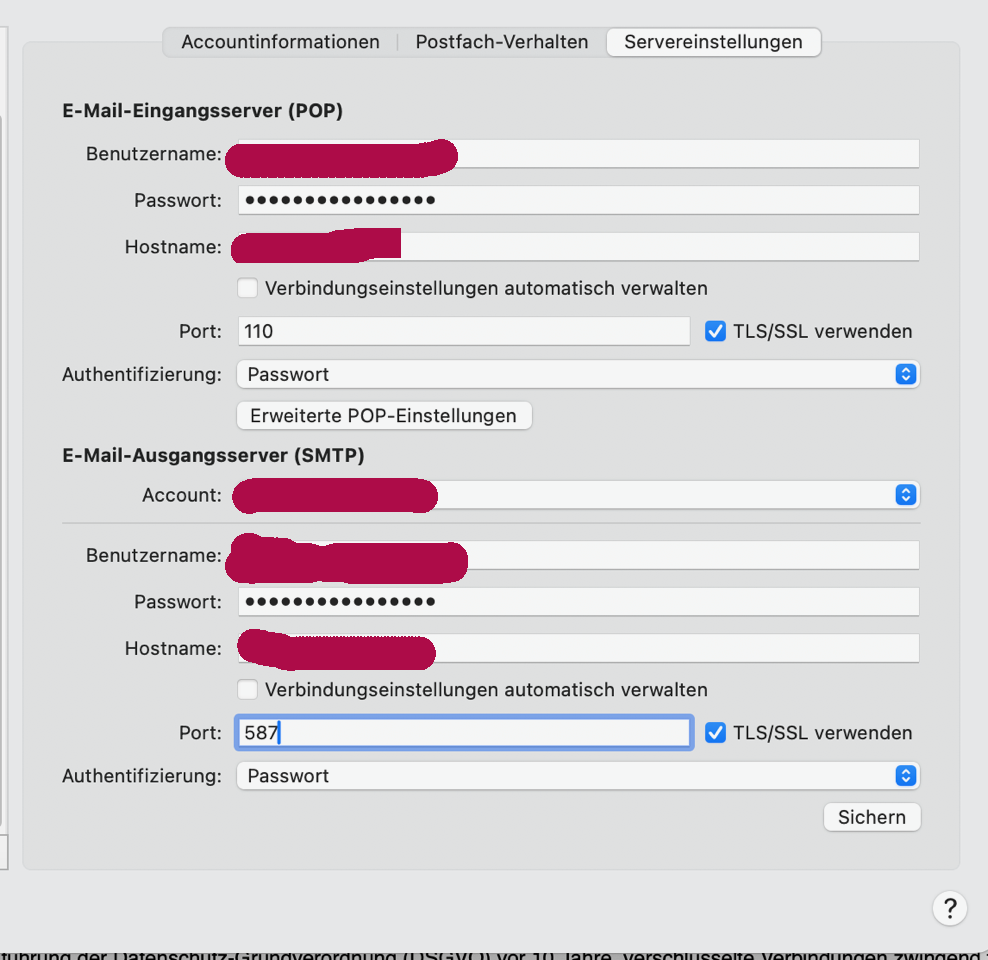
Mutmaßliches (latest) Outlook für MacOs
Ergo, haben Kunden wohl seit mehr als einem Jahrzehnt Ihre Emails im irrigen Glauben an die aktivierte Verschlüsselung stattdessen im Klartext abgeholt. Zur Zeit liegen mir passende Screenshots von Outlook vor, einzig die Versionsnummern fehlen noch, obwohl einer hatte noch Outlook 2007 im Einsatz. Gehen wir mal von der Annahme aus, daß alle nachfolgenden auch diesen Fehler hatten, da gleichlautende Meldungen auch von Outlook 2016 und neuer bekannt wurden, ist die Sicherheitslücke praktisch 20 Jahre im Einsatz und wäre nie aufgefallen, wenn Dovecot nicht was dagegen gehabt hätte.
„Regress“ und „Schadensersatz„
sind so Worte, die einem dabei durch den Kopf gehen. Den Schaden haben alle, die nach DSGVO zum Verschlüsseln der Emails verantwortlich gewesen sind und sich darauf verlassen haben, daß aktiviertes „SSL/TLS“ auch eine Verschlüsselte Verbindung bedeutet.
Den Serverbetreibern kann man hier keinen Vorwurf machen, da der Server nicht hellsehen kann, reagiert(e) er früher auf eine Klartextverbindung wie das im POP3 RFC vorgesehen ist. Selbst wenn man jetzt eine verschlüsselte Passwortübertragung auf Klartextport benutzt, ändert das nichts daran, daß die unverschlüsselte Übertragung der Email selbst für Unternehmen und Organisationen ein Gesetzesverstoß ist.
Wenn diese Meldung bei betroffenen Unternehmen publik wird, könnte Microsoft ein kleines finanzielles Loch entstehen.
Kleines Reddit Update:
Auf Reddit kam die Frage auf, wieso man unverschlüsselte Passwort-Auth überhaupt zulässt. Das ist ganz einfach: Kompatibilität. Auf diese Server prasseln Verbindungen aus der ganzen geographischen und IT-Welt ein, meint: Du hast keine Chance einen einheitlichen Standard durchzusetzen, ohne dabei 10% der Nutzer auf die Füße zu treten. Solange der Transportkanal modern verschlüsselt ist, besteht IMHO auch kein Grund auf eine komplizierte Methode auszuweichen, da es keinen zusätzlichen Schutz bietet. Wichtiger wäre, Verbindungen über Klartextports nur noch mit STARTTLS zu erlauben, weil das wirklich die Mail und nciht nur die Auth schützen würde.
Was so eine Änderung in der Realität bedeutet, möchte mal nur an einer Mailprogrammauflistung darstellen:
Thunderbird für Linux, MacOs, Windows
Outlook 2007 Windows 7
Outlook 2013 Windows 8
Outlook 2016 Windows 10+11
Outlook 2019 Windows 10+11
Outlook 2024 Windows 11
Outlook for MacOS ( diverse inkompatible Versionen)
AppleMail ( einer der schlimmsten Clienten überhaupt )
Evolution ( Linux )
The Bat ( das war echt übel damals )
Geary ( Linux )
k9 Mail
Mail for Android
Java Mailx
Avira AntVir
Kaspersky
Avast
Bitdefender
Norten
G Data
M$ Defender
Sophos
…
und die Liste geht weiter und weiter und weiter.
Alle diese Programme müssen mit dem Server reden können und jeder spricht ein klein wenig anders mit dem Server. Sehr beliebt bei Mailfehlern sind die Antiviren MITM-Attacken wo sich das Mailprogramm zu einem lokalen Proxy verbindet, statt zum echten Server. Da knallt es alle Naselang, weil diese Software mit der heißen Nadel gestrickt geworden zu scheint.
Wenn man in dem Konglomerat von Mailklienten auch nur auf die Idee kommt, Plaintext als Authmethode nicht mehr anzubieten, dann macht sich das direkt proportional auf Deinem Gehaltscheck bemerkbar, weil Deine Kunden nämlich folgenden Standpunkt einnehmen: „Lief doch gestern noch!“
Schon dieser Outlook Bug hat Wellen geschlagen und das will man als Anbieter nicht wirklich. Stellt Euch mal vor, was erst passiert, wenn man Plaintext abschaltet und die ganzen Antivirenprogramme failen… da bin ich dann im Urlaub 😀
Update:
1. es gibt einen Nachfolgeartikel zur Frage ob IMAP sicherer ist als POP3
2. Es kam die Frage nach der Oportunistischen Verschlüsselung auf, wobei es mit Klartext anfängt und dann wenns geht, verschlüsselt wird, wozu der Server STARTTLS können muß: Ja, können die natürlich alle.
3. Wenn Ihr darüber nachdenkt, setzt nicht Maßstäbe von 2026 ein, sondern von < 2010, da war SSL Luxus und vor allem meinte die SSL/TLS Checkbox auch wirklich SSL/TLS und gerade NICHT STARTTLS. Die meisten betroffenen Konten werden auch nicht in 2025 eingerichtet worden sein, sondern wurden über Jahrzehnte mit geupgraded, was das völlig erklären würde, weil das vom Entwicklerstandpunkt her ein echtes Problem darstellt, so lange Rückwärtskompatibel zu sein, ohne das was zerbricht.