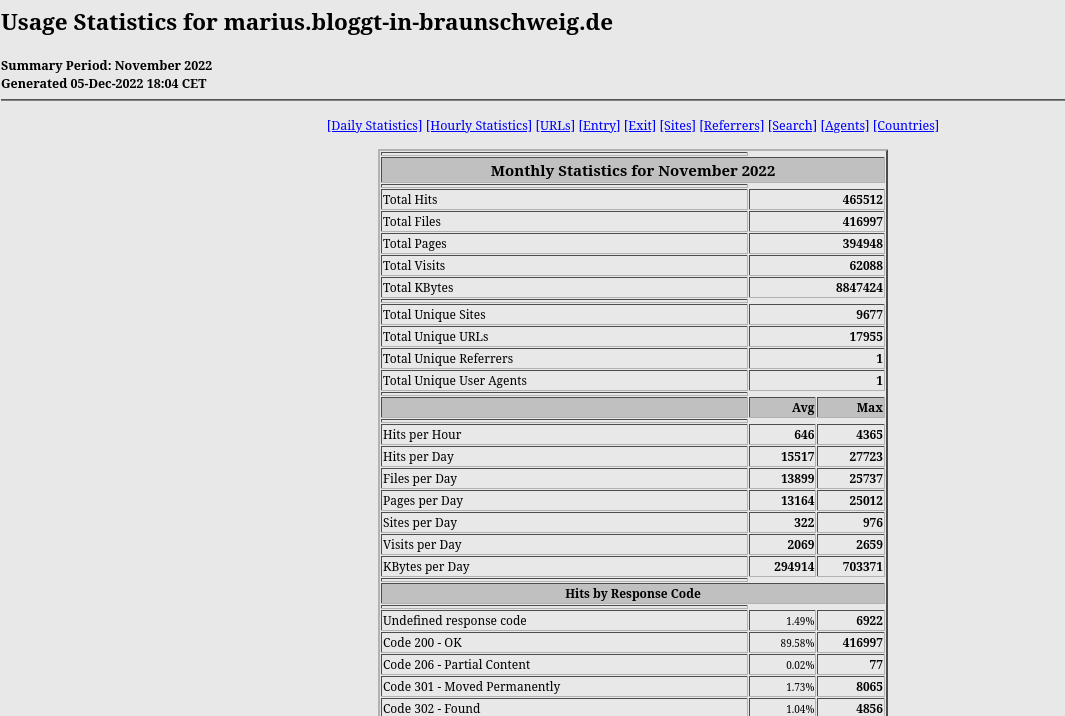
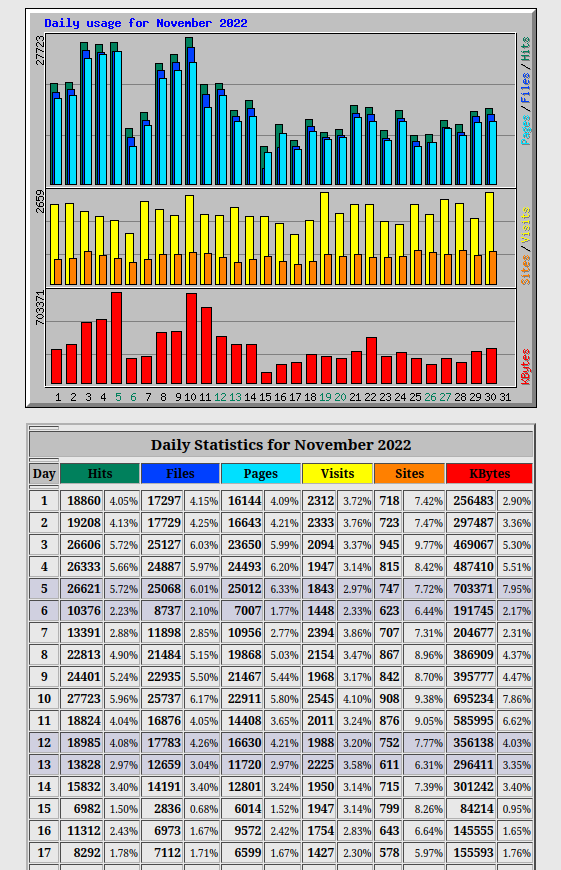
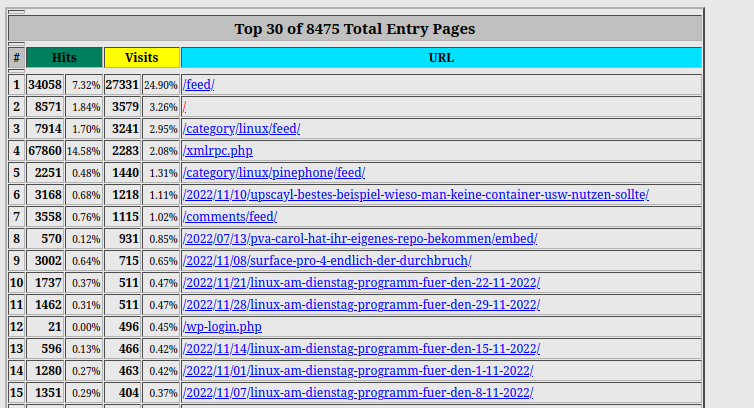
Wir haben hier natürlich für den November 2023 nur einen halben Monat, weil die Stats vom 13. des Monats sind. Eine kleine Rückschau zur Technik gibt es auch noch.
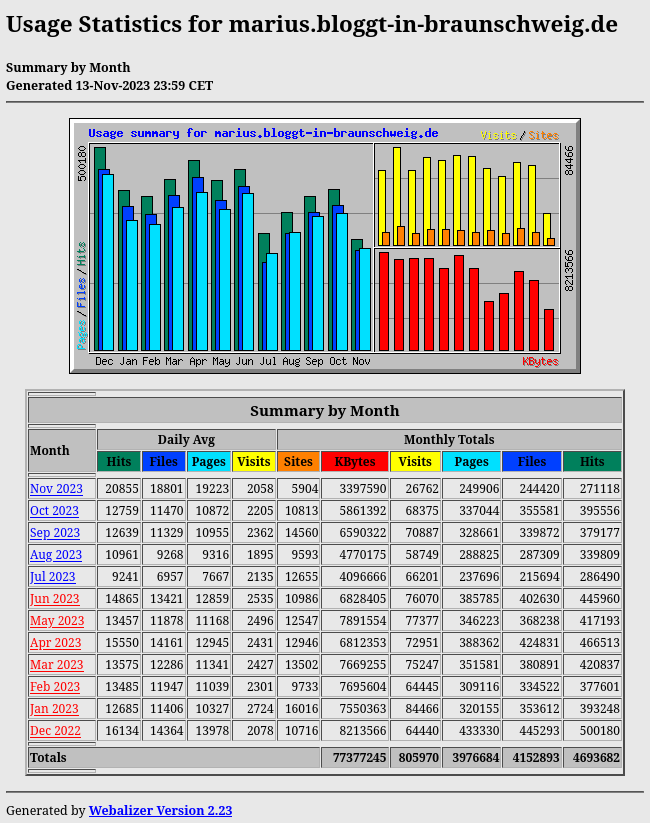
1 Jahr Blog Zugriffszahlen
Einfach nur Zahlen veröffentlichen kann jeder, deswegen ein kleiner Bericht aus dem Jahr des Caches.
Aus dem Leben eines Webcaches
Die meiste Zeit lief das Cache problemlos, sonst hätte ich es auch nicht benutzt. Die Vorteile liegen klar auf der Hand, weil die Zugriffszeiten massiv verbessert wurden. Allerdings stieg auch der Komplexitätsgrad der Serverkonfiguration an:
– DNS Proxies
– Backend-Webserver
– Fake DNS Server
– Cacheserver
Ohne groß ins Detail zu gehen, weil mit irgendwas muß man ja sein täglich Brot verdienen ;), kommen wir zu einer Besonderheit der Konstruktion: Der Backendserver hat eine andere IP als der Cacheserver.
Weil das so ist, muß man dem Cache irgendwie mitteilen, daß eine aufgerufene Domain eine ganz andere IP hat. Dazu benutzt man einen FakeDNS Server. Der war in Perl geschrieben und besteht im Prinzip nur aus einer einzigen Schleife: „Wenn wer fragt, sagt diese IP auf“. Das dumme daran ist, es ist Perl. Perl fällt aus bzw. für den Fragenden kommt einfach ab und zu mal keine Antwort.
„Keine Antwort“ meint aber im Cache: „Hey, der DNS Server ist tod.“ Was macht ein Cache wenn der Server „tod“ ist? Genau, es entfernt den DNS aus der Liste der aktiven DNS Server. Ziemlich blöd, wenn das nur ein Server ist 🙁 Also haben wir zwei konfiguriert und das Cache sollte Roundrobin machen. Machts aber nicht, auch wenn es in der Anleitung steht 😉
d.h. ein dritter FakeDNS mußte her und da hörte der Spaß auf. Statt noch ein Perlscript zu starten, wurde named als Forwarder konfiguriert. Das antwortet jetzt immer stabil auf Anfragen, weil es nur einmal am Tag nachfragt und geht so mit den arbeitsscheuen Perlscripten wohlwollend um.
Warum Perlscripte?
Weil um eine einzige IP auszugeben, ein vollwertiger PowerDNS nebst Datenbank vielleicht ein bisschen zu viel wäre. Dachte ich. Heute tendiere ich dazu mal entsprechend umzubauen, weil das den Komplexitätsgrad verringert und die Stabilität erhöht. Der Preis wird eine Datenbank basierte Pflege beinhalten, statt einfach ‚echo „domain.de 123.45.67.89“ >> fakedomainliste.txt‚ zu benutzen. Ein kleiner Preis, im Vergleich zum Stress durch die Ausfälle.
Wenn Ihr also plant WordPress mit einem Cache zu betreiben, dann macht es gleich richtig.
Praktischerweise konnte man aus diesem privaten Beispiel sehr viel für unsere Firma übernehmen und jetzt haben wir ein miniCloudflare, nur ohne Abhängigkeit von einer US-Firma \o/ Das reduziert die Last und macht Kunden glücklich.