Frage: „Wie macht man seiner Mutter an Halloween so richtig Angst?“ Antwort: man pimpt ihren Sprachassistenten mit der eigenen Stimme und ändert das Keyword auf seinen Namen 😉
F5-TTS – Ich habe mir selbst meine Stimme geklaut
Herzlich willkommen in der schönen neuen Welt, in der nicht einmal Eure Stimme noch Euch gehört! Der Diebstahl ist erschreckend einfach noch dazu.
Zuerst einmal installiert Ihr die nötige Software für die Stimmsynthese:
pip install git+https://github.com/SWivid/F5-TTS.git
Dann zieht Ihr euch von hier: https://huggingface.co/marduk-ra/F5-TTS-German/tree/main alle *safetensors und vocab.txt Dateien runter und parkt die auf Eurer Platte.
15 GB später braucht Ihr nur noch das hier starten: f5-tts_infer-gradio
10 Sekunden reichen zum Stimmenraub aus
Ihr bekommt dann dieses Webinterface zusehen, wenn Ihr http://localhost:7860/ aufruft
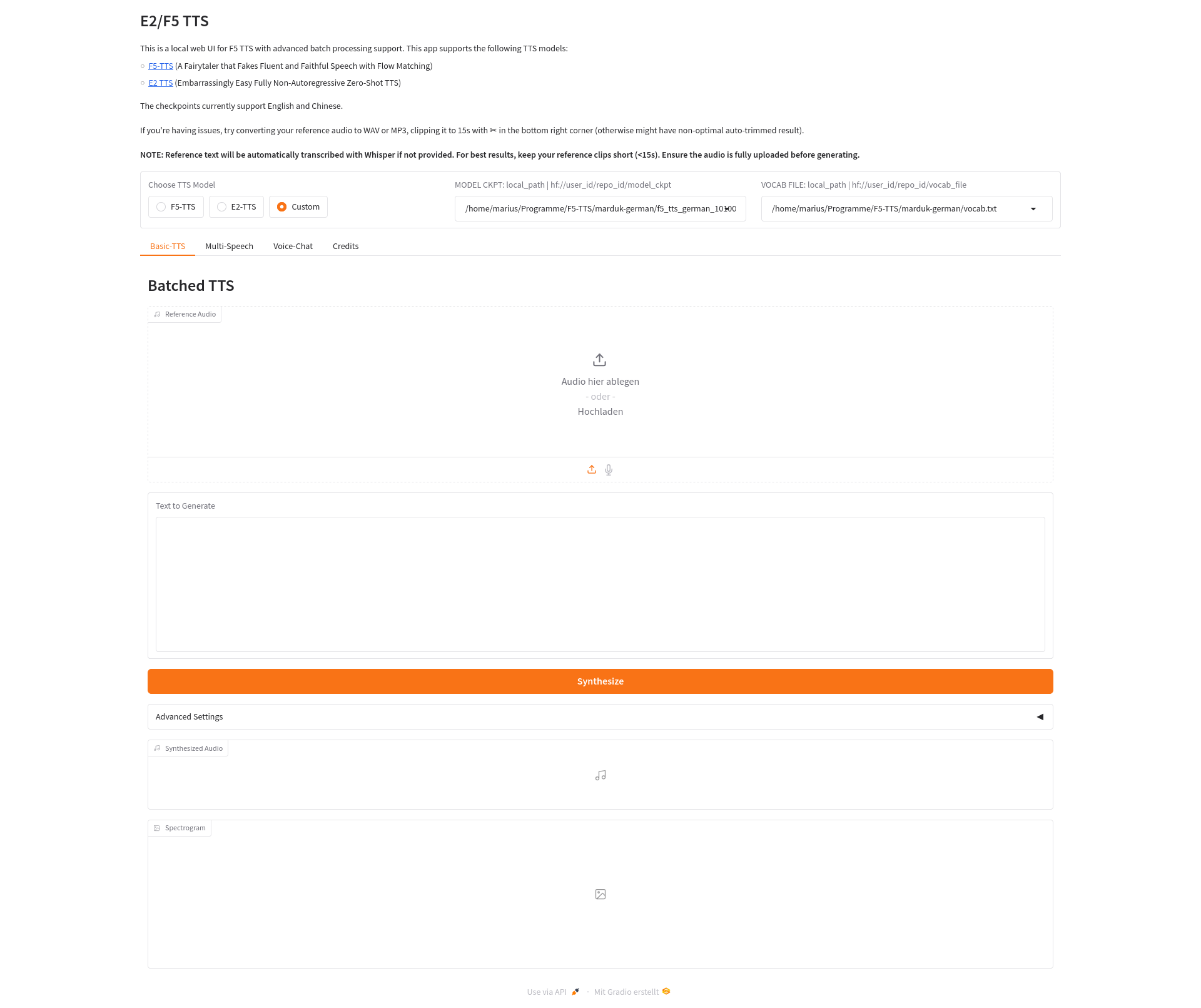 Damit Ihr eine Deutsche Aussprache bekommt, müßt Ihr zunächst das Custommodel aktivieren und jeweils die Pfade zu dem Tensor und dem Vocab File manuell in die Selectboxen eintragen, die da präsentiert werden. Das ist nicht intuitiv zu verstehen, klickt einfach auf die Box und schreibt was hin.
Damit Ihr eine Deutsche Aussprache bekommt, müßt Ihr zunächst das Custommodel aktivieren und jeweils die Pfade zu dem Tensor und dem Vocab File manuell in die Selectboxen eintragen, die da präsentiert werden. Das ist nicht intuitiv zu verstehen, klickt einfach auf die Box und schreibt was hin.
Als nächstes macht Ihr Audacity auf und nehmt einen Satz auf, für den Ihr 10-15 Sekunden braucht. Den speichert Ihr auf Eurer Platte als WAV File ab und in einer Textdatei schreibt Ihr den Satz auf.

Nun könnt Ihr bei „Text to Generate“ den gewünschten Text eingeben und drückt dann auf „Synthesize„. Es rattert dann etwas im Grafikkartenlüfter und X Sekunden später wirft er Euch unten das erzeugt Sprachfile ab und Ihr könnt es abspielen oder abspeichern.
Wie macht man jetzt eine Sprachausgabe daraus?
Als erstes bauen wir uns einen Bash-Wrapper, der eine Korrekturen am Text vornimmt und das Caching der Audiofiles managed, damit man den gleichen Satz nicht immer wieder neu erzeugen muß:
#!/bin/bash NOCACHE=0 if [ "$1" == "--nocache" ]; then NOCACHE=1 shift fi TEXT=$(echo "$2" | sed -r 's/\.([^ $])/\1/g' | sed -r 's/,([^ $])/ komma \1/g') if ! [[ "$TEXT" =~ !$ ]]; then if ! [[ "$TEXT" =~ \?$ ]]; then if ! [[ "$TEXT" =~ \.$ ]]; then TEXT="$TEXT." fi fi fi HASH=$(echo "$1$TEXT"| sha256sum | sed -e "s/ .*$//g") echo "$HOME/.cache/pva/audio/$HASH.mp3" if [ -e $HOME/.cache/pva/audio/$HASH.mp3 ];then play $HOME/.cache/pva/audio/$HASH.mp3 tempo 1 >/dev/null 2>/dev/null else port=$(env LANG=C netstat -lnap 2>/dev/null| grep -c 127.0.0.1:7860.*LISTEN) if [ "$port" -eq 0 ]; then echo "starting F5-TTS service" f5-tts_infer-gradio & 2>&1 1>/dev/null sleep 16 fi genfile=$(f5tts.py $1 "$2" |grep -v -E "(Loaded|ref_text|gen_text)" ) if [ "$NOCACHE" -eq "0" ]; then lame -V 5 -b 64 -B 224 $genfile $HOME/.cache/pva/audio/$HASH.mp3 >/dev/null 2>/dev/null fi rm -f $genfile fi
Die grünmarkierten Stellen müßt Ihr ggf. anpassen, weil das bei Euch mit dem Start schneller oder langsamer geht und Ihr vielleicht auch einen anderen Namen für das folgende Pythonprogramm haben wollt:
#!/usr/bin/python3
from gradio_client import Client, handle_file
import sys
import os
n = len(sys.argv)
if ( n == 2 ):
audio=handle_file('/home/marius/Programme/F5-TTS/Stimmen/default.wav')
file = open('/home/marius/Programme/F5-TTS/Stimmen/default.txt',"r")
rtext= file.readline()
file.close()
text=sys.argv[1]
else:
audio=handle_file('/home/marius/Programme/F5-TTS/Stimmen/'+ sys.argv[1] +'.wav')
file = open('/home/marius/Programme/F5-TTS/Stimmen/'+ sys.argv[1] +'.txt',"r")
rtext= file.readline()
file.close()
text=sys.argv[2]
client = Client("http://127.0.0.1:7860/")
result = client.predict(
new_choice="F5-TTS",
api_name="/switch_tts_model"
)
# print(result)
result = client.predict(
custom_ckpt_path="/home/marius/Programme/F5-TTS/marduk-german/f5_tts_german_1010000.safetensors",
custom_vocab_path="/home/marius/Programme/F5-TTS/marduk-german/vocab.txt",
api_name="/set_custom_model"
)
# print(result)
result = client.predict(
ref_audio_input=audio,
ref_text_input=rtext,
gen_text_input=text,
remove_silence=False,
cross_fade_duration_slider=0.15,
speed_slider=1,
api_name="/basic_tts"
)
print(result[0])
os.system( "play '"+ result[0] +"' 2>/dev/null");
Das Pythonprogramm nimmt zwei Argumente an: Stimmenbasisname und den Text den man sprechen will.
Das mit den Basisnamen ist leicht erklärt:
$ ls -la Programme/F5-TTS/Stimmen/ insgesamt 48032 drwxr-xr-x. 2 marius marius 4096 16. Dez 21:19 . drwxrwxr-x. 15 marius marius 4096 12. Dez 14:47 .. -rw-rw-r--. 1 marius marius 184 9. Dez 18:10 default.txt -rw-r--r--. 1 marius marius 1772176 9. Dez 18:10 default.wav -rw-r--r--. 1 marius marius 136 7. Dez 23:14 DMorty.txt -rw-r--r--. 1 marius marius 1159248 7. Dez 20:17 DMorty.wav -rw-r--r--. 1 marius marius 179 7. Dez 20:23 DRick.txt -rw-r--r--. 1 marius marius 1628108 7. Dez 20:24 DRick.wav -rw-rw-r--. 1 marius marius 109 9. Dez 17:20 Marius.txt -rw-------. 1 marius marius 1003864 9. Dez 18:35 Marius.wav
Ein Pärchen WAV und TXT Datei hat einfach den gleichen Anfangsnamen. So brauch man sich keine Dateinamen zu übergeben. Ihr setzt jetzt noch die Ausführungsrechte und seid fertig.
Verbesserungspotential
Ab und zu müßt Ihr mal was doppelt schreiben, weil das einfach weggelassen wird.
Wenn man ein gutes Ergebnis haben will, muß man auch eine Aufnahme der Stimme in Studioqualität nehmen.
„Viel“ hilft hier nicht weiter. 15s sind echt Max.
Die Zukunft wird schlimmer
Leider muß ich Euch jetzt viel Spaß wünschen, weil es einfach irre lustig war damit rumzuspielen. „Leider“ hat da soviel Missbrauchspotential, daß einem schlecht wird, wenn man mal darüber nachdenkt. Alleine schon in Firmen wird das beim Social Engineering so richtig einschlagen, weil man jetzt am Telefon die Stimme einer Person aus dem Unternehmen benutzen kann. Auch im Bankwesen ist der eine Katastrophe: die Nord/LB z.b. will eine Stimmbestätigung, wenn ein Sachbearbeiter im Auftrag des anrufenden Kunden was ändern soll. Jetzt ratet mal , was man da sagen soll : „Ja ich will, daß Sie … ändern.“ Mit F5 ist das ja jetzt wohl ein Witz als Absicherung.
Es wird ernsthaft vorgeschlagen ein Sicherheits/Erkennungswort in Familien auszuhandeln, um am Telefon Betrüger leichter zu entlarven!
Mahnende letzte Worte
1. Mit Eurer Stimme könnt ihr machen was Ihr wollt.
2. Mit Stimmen von anderen Menschen könnt Ihr für Euch zu Hause rumspielen, aber öffentlich zur Schaustellen dürfte mit ziemlicher Sicherheit ein Problem darstellen, wenn die Kopie sehr gut ist.
3. Die Stimme eines Dritten zu benutzen um andere zu schädigen, stellt garantiert eine doppelte Straftat dar.
4. Das Sicherheitswort „Seegurke“ ist schon von allen anderen Rick&Morty Fans belegt, denkt Euch was eigenes aus 😉
Links:
[1] https://github.com/SWivid/F5-TTS
[2] https://huggingface.co/marduk-ra/F5-TTS-German/tree/main